Overview
Javadoc
Take a look at the
Javadoc,
especially for
FileSystem
and
FileObject.
Contents
FileSystems API
The FileSystems API permits module authors to access files in a uniform manner: e.g. you may
be unaware of whether a file you are using is stored on local disk in
the user's repository, or stored in an auxiliary directory, or stored
in a JAR archive. Alternately, you may have reason to implement a custom file system - e.g. a vendor tool
being integrated into the IDE may have its own local or remote storage
of files in a special fashion; using this API, the rest of the IDE
will be able to seamlessly view your files.
This API pertains only to manipulating files on disk (or whatever
storage mechanism a file system may use), and makes no reference to
their contents nor to how they are being used elsewhere in the IDE
(beyond whether or not they are locked). If you are looking for
information on how to create custom content types, use the editor,
create Explorer nodes corresponding to files, etc., this API is not
the primary document you should be reading (although it may still be
useful).
From the perspective of the FileSystems API, all files consist of
byte streams (albeit with MIME types). Usually, the functionality of
this API will actually be used indirectly, via the
Loaders API,
which abstracts away most of the details of files and presents data in
terms of nodes.
Basic operations using the FileSystems API should be mostly familiar,
and are similar to any file-access system. (There are a few, such as
monitoring files, which are not universally available on system-level
file systems, so you may want to take special note of these.) This
section gives examples of the more common tasks associated with using
file systems.
At any given time, there may be several
FileSystems
in the NetBeans
Repository.
Some operations are specific to a particular file system, but often it
is possible to deal with files without having to keep track of which
file system they reside on - the mounted file systems then form a pool
of usable data files.
It is not too likely that you would need to mount a file system from
within code (normally the user would mount new filesystems in the
Explorer), but if that is necessary it is not difficult:
Repository repo=TopManager.getDefault().getRepository();
LocalFileSystem fs=new LocalFileSystem();
fs.setRootDirectory(new File("c:\\some directory\\"));
repo.addFileSystem(fs);
If you are looking for a particular file system, you might try something like:
// The master file system:
FileSystem mainFS=repo.getDefaultFileSystem();
// A local file system by path name:
LocalFileSystem fsByPath=null;
Enumeration all=repo.getFileSystems();
while (all.hasMoreElements()) {
Object o=all.nextElement();
if (o instanceof LocalFileSystem) {
LocalFileSystem lfs=(LocalFileSystem) o;
if (lfs.getRootDirectory().equals(new File("c:\\some directory\\"))) {
fsByPath=lfs;
break;
}
}
}
The Mount/ folder
The list of mounted filesystems is stored in the system file
system's folder Mount/. Each filesystem is represented by
some data object with an instance of it; typically this would be a
*.settings files, as described by the
Services API.
The order of mounts is given by the ordering of this folder.
Subfolders containing filesystems instances are also recognized.
You may read or write this folder as an alternative to using direct
Repository calls. However, no synchronization policy
between the mount folder and the actual contents of the repository is
defined, so this is probably not helpful to do at runtime.
On the other hand, it is fine to add mounts of filesystems to this
folder from a module layer; this is much preferable to trying to
procedurally mount the filesystem at startup. Since the objects
providing the filesystem instances may be displayed to the user in
settings, you are encouraged to provide nice display names and icons
for these files.
There are two XML DTDs provided by modules (not
guaranteed by the FileSystems API) which give you a convenient way to
add common types of mounts from a layer without any Java code.
- -//NetBeans IDE//DTD JavaLibrary//EN
XML files with this DTD will have a filesystem instance
corresponding to a ZIP or JAR file present somewhere in the IDE
installation (often the modules/ext/ directory). By
mounting such an instance you can add the archive to the user's
default classpath for compiling, executing, and debugging. Provided by
the java module. By convention such mounts are placed in
the Mount/java/ subdirectory, though this is not
required.
- -//NetBeans IDE//DTD JavadocLibrary//EN
This DTD produced instances of filesystems corresponding to
either ZIPs, JARs, or directories present in the IDE installation
(often a ZIP file in the docs/ directory), with the
proper filesystem capabilities set to be used as Javadoc. Provided by
the javadoc module. By convention such mounts are placed
in the Mount/Javadoc/ subdirectory, though this is not
required.
Normally, you will be looking for a file or folder by name, and will want to get the
FileObject
which represents it. The easiest way to do this is straight from the repository:
FileObject file=repo.find("my.package", "MySource", "java");
// OR:
file=repo.findResource("my/package/MySource.java");
(That got the first file named
my/package/MySource.java that could be found in any file
system. Occasionally you might want to find all files of a given name,
in different file systems; then you can use
Repository.findAll(...).)
If you need to get a file specifically from a particular file
system, just call find(...) or
findResource(...) on the file system object instead:
file=fs.find("my.package", "MySource", "java");
// OR:
file=fs.findResource("my/package/MySource.java");
(Note the similarity in usage to
ClassLoader.findResource(String).)
Or you may want to find the containing folder (represented also by
a
FileObject):
FileObject folder=repo.find("my.package", null, null);
To find all the folders and files directly contained in this
folder, you may use:
FileObject children[]=folder.getChildren();
Occasionally you may need to present a given file object as a URL
(usable only within the IDE, of course); for example, to display it in
a web browser. This is straightforward:
URL url=file.getURL ();
TopManager.getDefault().showUrl(url);
This example creates a subfolder and then a new file within that
subfolder:
FileObject subfolder=folder.createFolder("sub");
FileObject newfile=subfolder.createData("NewSource", "java");
If you want to delete or rename a file, you must first take out a
lock
on the file, to make sure that no one else is actively using the file
at the same time. Then you may perform the action on it:
FileLock lock = null;
try {
lock=newfile.lock();
} catch (FileAlreadyLockedException e) {
// Try again later; perhaps display a warning dialog.
return;
}
try {
// Rename it.
newfile.rename(lock, "NewSrc", "java");
// Delete it.
newfile.delete(lock);
} finally {
// Always put this in a finally block!
lock.releaseLock();
}
If you want to move a file into a different directory (or even file
system), you cannot use rename(...); the easiest way is
to use a NetBeans helper method:
FileObject someFile=repo.find("my.pkg", "MySource", "java");
FileObject whereTo=repo.find("your.pkg", null, null);
FileUtil.moveFile(someFile, whereTo, "YourSource");
Note that in the current API set, it is neither possible nor
necessary to lock folders (e.g. when creating new children), as
normally locks are used to protect data files from conflicts between
the Editor, the Explorer, and so on. If in the future there are
thread-related problems associated with improper simultaneous access
to the same folder, support for folder
locking could be added to the FileSystems API.
Similarly, there is no support currently for nonexclusive read
locks - if you require exclusion of writers during a read, you must
take out a regular write lock for the duration of the read. This is
not normally necessary, since typically only the Editor will be
reading and writing the contents of the file, and other file
operations do not involve information which could be partially
corrupted between threads. If necessary, the API includes
facilities for
read-many/write-one locks.
Reading and writing the contents of a data file is straightforward:
BufferedReader from=new BufferedReader(new InputStreamReader(someFile.getInputStream()));
try {
String line;
while ((line=from.readLine()) != null) {
// do something with line
} finally {
from.close();
}
FileLock lock;
try {
lock=someFile.lock();
} catch (FileAlreadyLockedException e) {
return;
}
try {
PrintWriter to=new PrintWriter(someFile.getOutputStream(lock));
try {
to.println("testing...");
to.println("1..2..3..");
} finally {
to.close();
}
} finally {
lock.releaseLock();
}
If you need to keep track of what is being done to a file by other
components, you can monitor it using normal Java events:
someFile.addFileChangeListener(new FileChangeAdapter() {
public void fileChanged(FileEvent ev) {
System.out.println("Contents changed.");
}
public void fileAttributeChanged(FileAttributeEvent ev) {
System.out.println(ev.getName() + ": " + ev.getOldValue() + " -> " + ev.getNewValue());
}
});
All events affecting existing files are actually fired twice, once
from the file itself and once from its containing folder, so you may
just want to listen on the parent folder. Also, file creation events
are fired on the folder only, of course:
FileObject someFolder=someFile.getParent();
someFolder.addFileChangeListener(new FileChangeAdapter() {
public void fileChanged(FileEvent ev) {
System.out.println("Contents of " + ev.getFile().getPackageNameExt('/', '.') + " changed.");
}
public void fileDataCreated(FileEvent ev) {
System.out.println("File " + ev.getFile().getPackageNameExt('/', '.') + " created.");
}
});
If you need influence the MIME type resolution process, you can register a MIMEResolver.
Resolvers are consulted for FileObjects on FileSystems that do not
provide any special means of finding MIME types (e.g. HTTP Content-Type headers).
To simplify this process you can register a MIMEResolver declaratively.
It is not only easier (no coding needed) but can be more efficient by
sharing results among multiple declared resolvers.
See the declarative MIME resolvers how-to for more information about this.
It is possible using the Filesystems API to implement a custom file
system from scratch which will appear in all ways to the IDE to be
interchangeable with the local or JAR file system types. This might be
useful for adding, e.g., support for browsing of URLs in the Explorer,
or integration with a proprietary file store used by an application
being integrated. There are no especially subtle issues involved in
doing this; but a number of methods must be implemented. This synopsis
will attempt to describe a fairly minimal set of things which should
be done to support a writable file system (read-only file systems are
of course easier); for other capabilities, the reader is referred to
the Javadoc.
Before reading all of the next two sections, be aware that for most
purposes it is sufficient to use a convenience implementation of
FileSystem which handles the rougher areas of caching,
synchronization, etc. that a file system implementation is likely to
encounter. FileSystem permits somewhat finer control, but
typically AbstractFileSystem should be used instead.
The basic technique to use for creating a new file system is to subclass
FileSystem,
specializing a few methods. The subclass should have a default
constructor and have its relevant properties settable using JavaBeans,
so that the user can manipulate the file system in the Explorer, under
the Repository. For example, the
LocalFileSystem
exposes the properties rootDirectory and
readOnly as Bean properties, so these will show up on the
Property Sheet for the file system node. You may also want to create a
BeanInfo
so that an appropriate icon will be chosen, tool tips will work on the
properties, and so on.
A particularly compelling reason to use BeanInfo is
that many file systems will not be valid at all until configured
somehow by the user, typically to indicate "where" their root
folder should be. For such file systems, you should provide a
Customizer
component that can configure a new file system in a user-friendly
fashion (it should implement this interface and be a
Component as well). To provide such a customizer, just
use the normal JavaBeans method of implementing
BeanInfo.getBeanDescriptor()
to create a BeanDescriptor which
specifies
the customizer.
The following methods ought to be implemented or overridden when
subclassing FileSystem:
FileSystem.getDisplayName()
should get a short name for the filesystem that is presentable to the
user. You may want to use Java localization for this. For example, an
HTTP filesystem could use a URL as the name.
- The
systemName property should be set appropriately
for this file system. A good system name is an internal identifier
which uniquely identifies this file system; its main purpose is so
that references to files on the filesystem may be serialized with only
this name as an indication of
which
file system they are associated with (and not need to store a
Java-level object reference). So, it ought to remain constant across
restarts of the IDE - do not use
Object.hashCode(),
for example! You should probably include both the class name for the
file system subclass, and some token indicating its root directory or
equivalent; for example,
com.mycom.myfs.HttpFileSystem/http://somewhere.com/file/system/root/.
You need not actually override
FileSystem.getSystemName()
and
FileSystem.setSystemName(String);
but you should call setSystemName(String) from whatever Bean
setter method sets the location of the file system, so that it will
always be updated.
FileSystem.findResource(String)
is perhaps the most basic method to implement in this class - it
expects a qualified file name within the file system, and should
return the file object corresponding to that file (if it exists).
Similarly,
FileSystem.getRoot()
should just get the top-level root folder of the file system.
FileSystem.isReadOnly()
should indicate whether or not the file system is (currently or by
design) read-only. For example, the JAR file system automatically
returns true; in the local file system, there is a
corresponding
setter method
allowing this to be a user-visible property which is dynamically
queried by destructive operations.
FileSystem.getActions()
should return an array of file-system-wide actions, i.e. operations
which could meaningfully be applied by the user to any file on this
file system. (If you have nothing you want in here, just return an
empty array.) For example, the local file system provides one global
action, Refresh, to resynchronize the file with that on disk; an HTTP
file system might provide a "Clear cache entry" option, etc.
FileSystem.prepareEnvironment(Environment)
should be overridden if the file system supports use in a VM-external
environment. Currently this means that it may be usefully added to a
system classpath for external execution, compilation, or debugging, so
it is only useful for file systems which somehow represent disk
directories or local JAR/ZIP archives, i.e. refinements of the
NetBeans-provided file systems. If you override it, just
add
an appropriate entry to the class path (e.g., the fully-qualified name
of a JAR file).
FileSystem.getStatus()
should be overridden for file systems that have some sort of
meaningful extra status that could be attached to files they own. The
most likely example is that a file system which implicitly handles
version control should have some way of indicating visually which
files have been checked out, are modified, and so on. By providing a
status recognizer, it may alter the names of resulting data nodes
(e.g. changing the displayed name of a data object from
MyForm to MyForm [missing]), or it may alter
the displayed icon in the Explorer (i.e. adding a question mark to the
corner of files whose status is unknown).
Implementing the actual files (and folders) is of course somewhat more
involved than the file system object. You should implement the
following methods at least:
- A
constructor
calling the base class's constructor. What arguments the constructor
takes is up to you, however, and it should probably be
package-private: it need only be called from implementations of
FileSystem.findResource(String)
and
FileSystem.getRoot().
FileObject.getFileSystem()
to indicate which file system it is a part of.
FileObject.getFileObject(...),
FileObject.getChildren(),
and
FileObject.getParent()
are the basic methods with which you implement the file system's hierarchy.
Note that FileSystem.findResource(String) could easily be
implemented in terms of FileSystem.getRoot() and
FileObject.getFileObject(...).
FileObject.isData(),
FileObject.isFolder(),
FileObject.isRoot(),
FileObject.getName(),
and
FileObject.getExt()
permit further traversal of the file system hierarchy starting from a
file of unknown name and position.
FileObject.createData(...),
FileObject.createFolder(String),
FileObject.rename(...),
and
FileObject.delete(FileLock)
are the methods to override to support basic file-manipulation
operations on a writable file system.
You must also implement
FileObject.lock()
to create some sort of object which may be used to lock files for
rename(...) and delete(...); this method
should likely be synchronized, and should keep track of whether there
is already a
FileLock
unreleased and associated with the file object.
FileObject.getInputStream()
and
FileObject.getOutputStream(FileLock)
are used to obtain read/write access to the actual contents of the
file. Note that getOutputStream requires a lock, so you
do not need to worry about simultaneous write attempts.
FileObject.getSize()
must also be implemented for access to content to be useful, as well
as
FileObject.isReadOnly().
FileObject.lastModified()
is used during compilation (e.g.) to check whether certain
automatically-created files (such as Java classfiles) are out of date.
FileObject.addFileChangeListener(FileChangeListener)
and
FileObject.removeFileChangeListener(FileChangeListener)
may either be empty, in the case of a permanently read-only file system, or may use the normal
EventListenerList
support class, etc. You may also want to use
FileObject.fireFileChangedEvent(...)
and similar methods for convenience. In any case, on a writable file
system you should fire events for all the supported methods in
FileChangeListener.
FileObject.getAttributes(),
FileObject.getAttribute(String),
and
FileObject.setAttribute(...)
permit arbitrary name-value pairs to be associated with particular
files on a file system. For example, an HTTP file system might
store HTTP header lines as attributes if they were needed by some
other component.
Also, many parts of the IDE store their own information in such
attributes - for example, the arguments for a file to be executed
are stored by
ExecSupport
in the file's attributes. So for writable file systems, these
attributes should generally be supported; normally the abstract file system will do this for you.
Similarly,
FileObject.setImportant(boolean)
may have a dummy body but may also be used to control the backup
status of files, etc. For many filesystems this can be ignored;
typically version-control filesystems should use this to
automatically exclude "scratch" files, and similarly for the MS-DOS
"archive" attribute (if that were accessible from Java). For
example, a form (created by the Form Editor) will mark
*.form and *.java files as important, but
not *.class files (since they can be regenerated
easily).
FileObject.isValid()
should, if possible, check whether the actual storage mechanism of the
file is still working - whether the file still exists on disk and has
not been erased without the IDE's knowledge, for example. It should be
fast, as it will be called quite frequently, so you should
avoid network access and so on.
FileObject.getMIMEType()
may need to be overridden for file systems that would have special
access to information about the meaning of a file's contents beyond
what is indicated by its extension (e.g. HTTP
Content-Type headers).
The default behavior is to consult available MIMEResolvers.
Filesystems should not override this behavior unless they have a concrete source of
information about MIME type beyond e.g. file extension; and if it is overridden,
the default behavior of consulting MIME resolvers should be used as a fallback.
A module can influence the MIME resolution process by registering a MIMEResolver object,
most easily done using a
declarative XML file.
This convenience implementation does much of the hard work of
FileSystem and is generally more pleasant to create
subclasses of. Refer to the previous sections for details on what all
of these features do and how they interact with the rest of the
system.
Besides what is mentioned here, the
AbstractFileSystem subclass should still be
configurable as a JavaBean, just like the regular method.
First of all, you need not separately implement a file object - this
is taken care of for you. You need only provide some information about
how essential actions should be carried out.
You should still implement
AbstractFileSystem.getDisplayName() to set the display name.
You may cause the file system to automatically refresh itself at
periodic intervals, in case it is not possible to be notified of
changes directly. To do so, call
AbstractFileSystem.setRefreshTime(int),
e.g. from the constructor.
AbstractFileSystem.refreshRoot()
must be called if the file system supports changing of its root
directory (as the local file system does, for example).
Most of the meat of the implementation is provided by setting
appropriate values for four protected variables, which should be
initialized in the constructor; each represents an implementation of a
separate interface handling one aspect of the file system.
List member
The variable
AbstractFileSystem.list
should contain an implementation of
AbstractFileSystem.List.
This only specifies a way of accessing the list of children in a folder.
Info member
AbstractFileSystem.info
contains an
AbstractFileSystem.Info
which provides basic file statistics.
It also specifies the raw implementation of three basic types of
actions: getting input and output streams for the file; locking and
unlocking it physically (optional and not to be confused with locking
within the IDE); and marking it as unimportant, i.e. not to be
archived (again optional).
Change member
AbstractFileSystem.change
is an
AbstractFileSystem.Change
which provides the interface to create new folders and files; delete
them; and rename them (within the same directory).
Attribute member
AbstractFileSystem.attr
is an
AbstractFileSystem.Attr
allowing the IDE to read and write serializable attributes
(meta-information) to be associated with the file.
Here a word of caution is in order. The IDE frequently uses these
attributes for specific purposes, e.g. storing user settings for the
arguments used to execute a class. It is thus fairly important that
they be implemented correctly on a writable file system. Since many
concrete storage mechanisms (such as local disk) do not provide any
means of associating attributes in this way, the API provides a
default implementation which stores them in a special file (one per
folder), currently named .nbattrs (formerly
filesystem.attributes). The newer .nbattrs
files are XML-based; simple attribute values (primitive types,
Strings, and URLs) are stored directly, and
more complex objects are serialized and the hexadecimal stream placed
in the XML. In the future it is expected that there will be a
mechanism for other attribute value types to be stored as proper XML.
In order to use this implementation, you should set the
attr variable to be an instance of
DefaultAttributes.
You need only provide the other three behaviors in its constructor for
it to function correctly - it manipulates the attribute files exactly
the same way as regular files would be manipulated.
However, it is undesirable for the attribute files to appear
externally as real files on the filesystem, since these would leave
them open to accidental modification, and they should of course not be
seen by the user. So, DefaultAttributes also implements
AbstractFileSystem.List as a filter, which
simply removes the attribute file before passing along the normal
children. To use this, you should have one private list object
containing your raw implementation of child scanning in the underlying
storage; then provide this to the DefaultAttributes in
its constructor; and finally use the DefaultAttributes
object for AbstractFileSystem.list as well as
AbstractFileSystem.attr.
If your file system provides very little functionality, but only a
minor hook or two, it may be more convenient to simply subclass
LocalFileSystem or JarFileSystem. This
should generally be straightforward, provided you remember always to
call the superclass method in an appropriate fashion when
overriding. For both of these filesystems you can override protected
methods corresponding to the methods in the AbstractFileSystem
methods (LocalFileSystem uses DefaultAttributes so
attribute-related methods are not provided). Of course, if you wind up
overriding more than a couple of these methods, you might as well just
subclass AbstractFileSystem to begin with.
You may use the
Modules API
to add a new type of filesystem to the system. However a better technique
is to define a
service template
for the filesystem in the folder Templates/Mount/ (or
some subfolder thereof), which is both more efficient and more
flexible.
The FileSystems API includes a couple of special implementations which
are used by the core of the IDE to assemble the application, and could
also be used by module writers in some circumstances.
This file system has no form of storage in and of itself. Rather, it
composes and proxies one or more "delegate" file systems. The result
is that of a "layered" sandwich of file systems, each able to provide
files to appear in the merged result. The layers are ordered so that a
file system in "front" can override one in "back".
Creating a new MultiFileSystem is easy in the simplest
cases: just call its
constructor
where you can pass it a list of delegates. If you pass it only
read-only delegates, the composite will also be read-only. Or you may
pass it one or more writable file systems (make sure the first file
system is one of them); then it will be able to act as a writable file
system, by default storing all actual changes on the first file
system.
This class is intended to be subclassed more than to be used as is,
since typically a user of it will want finer-grain control over
several aspects of its operation. When subclassed, delegates may be
changed dynamically
and the "contents" of the composite file system will automatically be
updated.
One of the more common methods to override is
createWritableOn(String),
which should provide the delegate file system which should be used to
store changes to the indicated file (represented as a resource path).
Normally, this is hardcoded to provide the first file system (assuming
it is writable); subclasses may store changes on another file system,
or they may select a file system to store changes on according to (for
example) file extension. This could be used to separate source from
compiled/deployable files, for instance. Or some filesystems may
prefer to attempt to make changes in whatever file system provided the
original file, assuming it is writable; this is also possible, getting
information about the file's origin from
findSystem(FileObject).
Another likely candidate for overriding is
findResourceOn(...).
Normally this method just looks up resources by the normal means on
delegate file systems and provides the resultant file objects. However
it could be customized to "warp" the delegates somehow; for example,
selecting a different virtual root for one of them.
notifyMigration(FileObject)
provides a means for subclasses to update some state (for example,
visual annotations) when the file system used to produce a given file
changes dynamically. This most often happens when a file provided by a
back delegate is written to, and the result stored on the foremost
delegate, but it could occur in other situations too (e.g. change of
delegates, removal of overriding file on underlying front delegate,
etc.).
When new files are added to the MultiFileSystem,
normally they will be physically added to the foremost delegate,
although as previously mentioned they can be customized. When their
contents (or attributes) are changed, by default these changes are
again made in the foremost delegate. But what if a file is deleted?
There must be a way to indicate on the foremost delegate that it
should not appear in the composite (even while it remains in one of
the delegates). For this reason, MultiFileSystem uses
"masks" which are simply empty files named according to the file they
should hide, but with the suffix _hidden. Thus, for
example, if there is a file subdir/readme.txt_hidden in a
front delegate it will hide any files named
subdir/readme.txt in delegates further back. These masks
are automatically created as needed when files are "deleted" from
MultiFileSystem; or delegate filesystems may explicitly
provide them. Normally the mask files are not themselves visible as
FileObjects, since they are an artifact of the deletion
logic. However, when nesting MultiFileSystems inside
other MultiFileSystems, it can be useful to have
delegates be able to mask files not provided by their immediate
siblings, but by cousins. For this reason, nested subclasses may call
setProgagateMasks(true)
to make the mask files propagate up one or more nesting levels and
thus remain potent again cousin delegates.
This file system is a simple implementation which is read-only and its
contents derived exclusively from an XML file. It is thus useful for
configuration and so on where a fixed set of (typically small) files
is needed. Its primary use is in modules which wish to provide a layer
for the default file system in the IDE (which stores configuration of
various sorts).
Its Java API is very slim: common uses need only call the
constructor
taking a URL to the XML file as argument.
The XML format is also relatively simple. There is an
online DTD
for it, but descriptively: the document element is
<filesystem> and corresponds to the root folder;
subfolders are represented with the <folder>
element; and files within folders with the <file>
element. Files and folders must have names, with the name
attribute. Files need not specify contents, in which case they will be
zero-length; or they may specify contents loaded from some other
resource (url attribute, treated as relative to the base
URL of the document itself); or for small textual contents, the
contents may be included inline inside the element, typically using
the CDATA syntax. Attributes may be specified on folders
or files as empty <attr> elements; the name must be
supplied, and the value in one of several formats: primitive types,
strings, URLs, arbitrary serialized objects in hexadecimal, or
computed on the fly by calling the default constructor of some class,
or a static method (the method may be passed the file object in
question and/or the attribute name, if you wish).
So as an example to install a template:
<?xml version="1.0"?>
<!DOCTYPE filesystem PUBLIC
"-//NetBeans//DTD Filesystem 1.0//EN"
"http://www.netbeans.org/dtds/filesystem-1_0.dtd">
<filesystem>
<folder name="Templates">
<folder name="Other">
<file name="foo.txt">
<![CDATA[some contents here...]]>
<attr name="template" boolvalue="true"/>
<attr name="SystemFileSystem.localizingBundle"
stringvalue="com.foo.module.Bundle"/>
<attr name="templateWizardURL"
urlvalue="nbresloc:/com/foo/module/foo-template-help.html"/>
<attr name="templateWizardIterator"
newvalue="com.foo.module.FooTemplateIterator"/>
</file>
</folder>
</folder>
</filesystem>
where FooTemplateIterator contains a public constructor
taking no arguments.
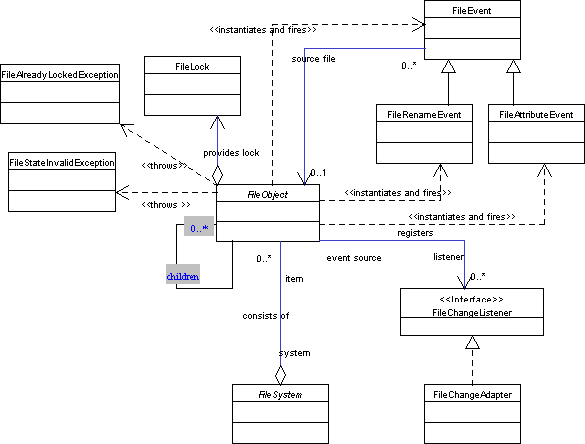
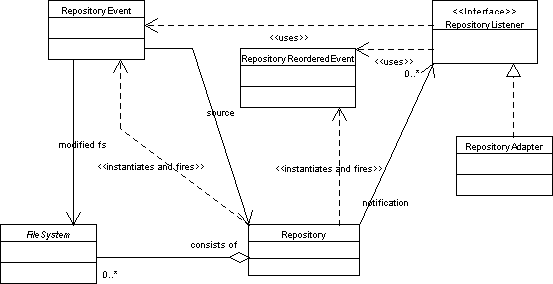
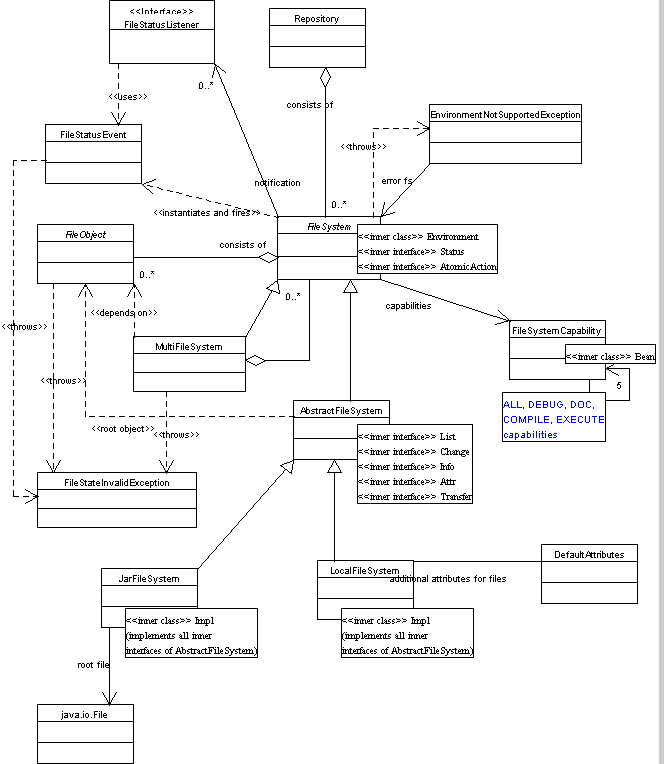
UML representation of FileSystems API is divided to three class diagrams.
FileObject and
Repository diagrams represent
regular usage of the API, while
FileSystem diagram is more
useful for developers that will want to implement their own filesystem.
Built on December 12 2001. | Portions Copyright 1997-2001 Sun Microsystems, Inc. All rights reserved.