Most hard-core project courses put emphasis on the design aspect. Here are some things to keep in mind when designing your system.
A software design is a complex thing, especially, if you do not use abstraction to good effect. The design should be done at various levels of abstraction. At higher levels, you visualise the system as a small number of big components while abstracting away the details of what is inside each component. Once you have a good definition of what each of those components represent and how they interact with each other, you can move to the next lower level of abstraction. That is, you take each one of those components and design it using a small number of smaller components. This can go on until you reach a lower level of abstraction that is concrete enough to transform to an implementation.
We should try to keep different 'concerns' of the system as separated from each other as possible. For example, parsing (and things related to the 'parsing' concern) should be done by the parser component, and everything that has to do with sorting should be done by the sorter component.
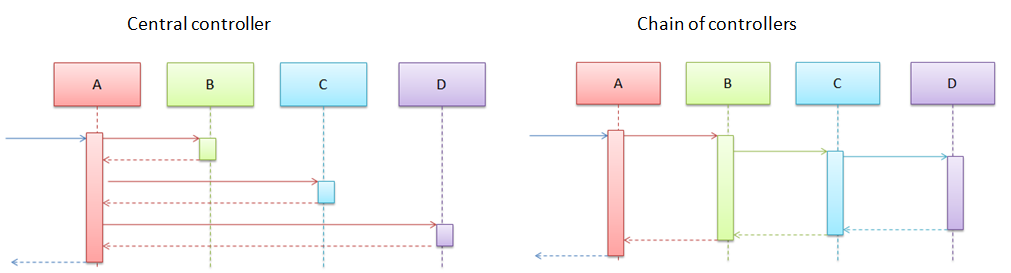
Otherwise known as the Law of Demeter, the 'don't talk to strangers' principle advocates keeping unrelated things independent of each other. For example, if the parser component can function without any knowledge of the sorter component, then the sorter is a stranger to the parser. That means the parser should not have any reference to the sorter (e.g. can you compile the parser without compiling the sorter?)
A classic example where this principle applies is when choosing between a central controller model and chain of controllers model. The former lets you keep strangers as strangers, while the latter forces strangers to talk to each other. Notice how one design below lets B and C remain strangers while the other forces them to know each other.
Along the same vein, minimise communication between components. Avoid cyclic dependencies (e.g. A calls B, B calls C and C calls A)
A component should reveal as little as possible about itself. This is also known as information hiding. For example, other components that interact with your component should not know in what format your component stores data and they should not be allowed to manipulate those data directly.
Fred Brooks contends that (in the book The Mythical Man-Month)
... the conceptual integrity is the most important consideration in system design. It is better for a system to omit certain anomalous features and improvements, but to reflect one set of design ideas, than to have one that contains many good but independent and uncoordinated ideas.A student team is a team of peers that usually does not have a designated architect to dictate a design for others to follow. Everyone may want to have their say in the design. However, after discussing all alternative designs proposed, you should still choose one of them to follow, rather than devise a design that combines everyone's ideas. Combining ideas into one design has its merits, but do not do it just for the sake of achieving a compromise between competing ideas. If in doubt, get your supervisor's opinion as well.
Similar problems should be solved in a similar fashion. Sometimes, it pays to solve even slightly different yet largely similar problems in exactly the same way. It makes programs easier to understand. In other words, do not go out of your way to customise a solution to fit a problem precisely. It may be better to preserve the similarity of the solution instead.
Patterns (design patterns [http://tinyurl.com/wikipedia-patterns], as well as other types of patterns such as analysis patterns, testing patterns, etc.) embody tried-and-tested solutions to common problems. Learn patterns and use them where applicable.
Most patterns come with extra baggage. Do not use patterns for the sake of using them. For example, there is no need to apply the Singleton pattern to every class that will have only one instance in the system; use it when there is a danger of someone creating multiple instances of such a class.
Try to make the design as simple as possible (but no simpler!). Simple yet elegant designs are much better than complex solutions: The former is much harder to achieve however, but that is what you should strive for. Given any design, try to see whether you can simplify it. Resist any change that makes it more complex.
When many other components use a given component (i.e. the component has high fan-in), this is a good thing because it increases reuse. When a given component uses many other components (i.e. it has high fan-out), this is not a good thing because it increases coupling.
Some problems have an obvious and simple brute force solution. Do not dismiss this solution too quickly in your haste to look for a smarter solution. If you can afford it, give this brute force solution a chance; it may be all you need.
Trim all parts of the design that are not immediately useful to the system. It does not matter how elegant they are, how proud you are of dreaming them up, and how hard you worked at building them. The same applies to code.
Some non-functional qualities need to be incorporated from the design stage. One non-functional quality rarely mentioned in the specification and often forgotten in the design is the testability. Improving testability improves many other qualities of the design.
Hoare wasn't kidding when he said "Premature optimization is the root of all evil in programming". Opt for a simple design. If it is fast enough, stick with it. If it is not, find the real bottlenecks (profiling tools [Chapter 9] can be used for this purpose) and optimise accordingly.
Caveat: This does not mean that you should start with a stupid design. Some designs are obviously inefficient and should be discarded immediately. Start with a design that is, in Einstein's words "as simple as possible, but no simpler".
During analysis and design, consider all the known facts but do not fret too much about unknowns. If you are given a concrete and stable specification (e.g. writing a parser for a given language) it would be stupid to start with a design that does not take the entire specification into account. Such short-sighted designs will eventually require change, causing rework that could have been avoided. On the other hand, if you are defining a first-of-a-kind exploratory system for an unspecified user base, go for a design with a reasonable degree of flexibility; do not worry about all the nitty-gritty issues that it might or might not have to face later.
Documenting design often requires wrestling with UML editors and other diagramming tools. Therefore, it is very frustrating when we have to modify those documents as the design changes over time.
While designs should be documented as they are done, there is no need to start creating well-polished design documents right away. You can keep the documentation as low-maintenance rough sketches (with none of the important points missing) until the design is sufficiently stable. For example, you can take a photo of the whiteboard on which you drew the initial design, print it out, do your (minor) modifications on the hard copy, and convert it to a digitised UML diagram much later.
An API (Application Programming Interface) is a set of operations a software component (i.e. a system, a sub-system, class) provides to its clients. For example, here [http://tinyurl.com/stringAPI] is the API of the Java String class.
A well-defined API is not only easy to use, but it gives the implementers (of that component) flexibility in implementation. As clients of the component write code against the API (i.e. they only know about the API), implementers have the freedom to change internal implementation details. As long as the API remains stable, client code will not have to change. For example, as clients of the String class, we only know its API, but we can use it without knowing how it is implemented internally.
When we design a system, we should use APIs to achieve a similar degree of freedom between components so that developers of those components can work independently of each other. For example, let us assume our system has two sub-systems: front-end and back-end. Let us also assume that the front-end uses the back-end. In this case we must first define the back-end API. Once that is defined, both the front-end team and the back-end team can start work in parallel instead of the front-end team waiting until the completed back-end is available. That is because the front-end team is assured that the back-end will support the agreed API irrespective of how it will be implemented. Therefore, defining APIs is an integral part of designing software.
To define the API of a component, we must clearly understand the needs of the component's clients. The best way to discover an API of a component, therefore, is to talk to those who will use the component. For example, clients for the back-end include front-end. Therefore, the back-end API should be defined based on a discussion between the front-end team and the back-end team. Similarly, if you are writing a utility class to be used by many other classes in the system, you must define the API of your class based on the requirement of those client classes.
API operation names and parameter names should have intuitive meanings. E.g. setParent(parent, child) is more meaningful than setPrt(p,c). The chapter on 'implementation' has some more tips about naming.
If you have two operations addVariable() and removeVar(), you are not naming them consistently. Name the second operation removeVariable(), or the first operation addVar(). When using a consistently named API, users can simply deduce the correct operation to call without actually checking the API documentation.
The API should not reveal clues about the internal structures. For example, addToVarHashtable() reveals that we are using a Hashtable to store variables; what if later we want to change it to a Vector?
Make sure the component provides a complete set of primitive operations. You can add more specialised operations as necessary and implement them using the primitive operations. Even if you do not supply those specialised operations, clients will be able to accomplish such specialised tasks using the primitive operations. This avoids polluting the API with highly-specialised yet rarely-used operations.
If the API is becoming too long, may be the component is doing more than it should; consider splitting the component if appropriate. Or else, the component may be supporting too many operations to achieve the same thing. Strive to achieve a minimal yet complete API (refer tip 10.26).
Having multi-purpose methods causes unnecessary complexities, performance penalties, and misunderstandings. Make each operation do one thing and only one thing. Rather than have a writeToFile(string text, boolean isAppend) where the second parameter indicates whether to overwrite or append, have two methods appendToFile(string text) and overwriteFile(string text).
Caveat: An over-enthusiastic application of this guideline could lead to a bloated API [see tip 10.27]
This is another way to look at the previous two points. On the one hand the API should provide direct and easy-to-use ways to accomplish common tasks. On the other hand, rarely-used highly-specialised tasks need not be directly supported; instead, we can let clients implement these operations themselves, using a combination of existing primitive operations.
An API is a contract (between the implementer of the component, and users of the component); just like any contract, promising less makes it easier to deliver. E.g. If an operation is for calculating the root of positive integers, it should be findRoot(PositiveInt i), not findRoot(int i)
An operation should throw exceptions to indicate exceptional situations (e.g. when an input file was not found). These should be clearly specified in the API. A common mistake is to specify only the typical behaviour.
When a set of steps is always done together in the same sequence, capture that as one atomic operation instead of having separate operations for each step. For example, imagine that your component has to parse a file that contains some program code, and create the corresponding abstract syntax tree (AST).
Clearly the first option is better; it makes the API shorter and reduces chances for error (what if we call parse method without calling the setFileName method first?).
Operations in the API should be in tune with the abstraction the API represents. For example, a Parser API should use terms related to Parsing. This is also applicable to the exceptions thrown by the API. For example, a Parser API should throw exceptions that are related to a Parser.
Try to keep all operations of an API on the same level of abstraction. An API that has a mix of high-level and low-level operations is harder to understand. For example, the File API should not mix high-level operations such as open(), close(), append(String) with low-level operations such as those for direct manipulation of bits inside the file.
While we try to keep APIs stable, it is not uncommon for changing client requirements to force changes in existing APIs. If you have multiple clients, make sure that a change requested by one client does not adversely affect the other clients.
Furthermore, we sometimes evolve the API as our understanding of the client requirements improves.
It is OK to specify the data types in the operation header using symbolic names, and later refine them into concrete types. For example, the return type can be specified as list-of-TreeNodes and later refined to TreeNode[] or ArrayList<TreeNode>.
The API documentation should be precise, unambiguous, concise and complete. Do not leave room for the client to make assumptions. Instead, explicitly specify what a method does. You can use this API description of the Java String class as a guiding example when documenting APIs, although yours need not be as elaborate.
Find a way to generate the API documentation from the code itself and comments therein. An example of this strategy in action is the Java API documentation generated by Javadoc comments embedded in the code. Doxygen is another tool that can help here.
Any suggestions to improve this book? Any tips you would like to add? Any aspect of your project not covered by the book? Anything in the book that you don't agree with? Noticed any errors/omissions? Please use the link below to provide feedback, or send an email to damith[at]comp.nus.edu.sg
 |
Sharing this book helps too! |
---| This page is from the free online book Practical Tips for Software-Intensive Student Projects V3.0, Jul 2010, Author: Damith C. Rajapakse |---