|
Verifying Linearizability via Optimized Refinement Checking |
Yang Liu, Wei Chen, Yanhong A. Liu, Jun Sun, Shao Jie Zhang and Jin Song Dong
Overview
This page contains supplementary material for our paper:”Verifying Linearizability
via Optimized Refinement Checking”.
This page is maintained by Shao Jie Zhang
.2.
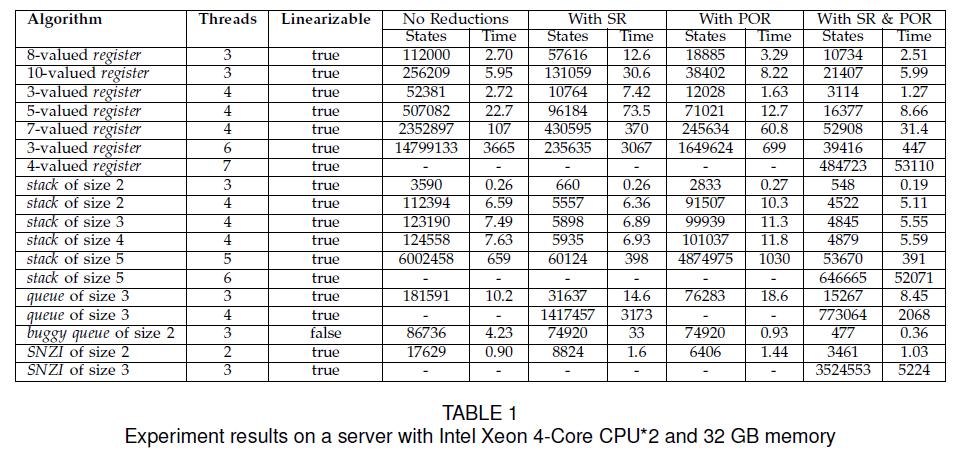
All model files in
this experiment
Our data archive can be downloaded as a single zip file:
{kind=link}