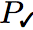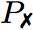|
|
CoREBench: Realisitic, complex regression errors
Why do we need it?
In software engineering research, we require benchmarks in order to
evaluate and compare novel regression testing, debugging and repair
techniques, yet actual regression errors seem unavailable.
The most popular error benchmarks, Siemens
and SIR, contain mostly manually seeded regression errors.
Developers were asked to change the given programs slightly such that they contain errors of
varying detectability, i.e., that were more or less difficult to expose. However, in our
recent study
we find that such seeded regression errors are significantly less complex than
actual regression errors, i.e., they require significantly less substantial fixes than actual regression errors.
This poses a threat to the validity of studies based on seeded error! We propose CoREBench for the study
of complex regression errors.
[Read the Paper] [Download CoREBench] [How to Cite]
What is it?
CoREBench is a collection of 70 realistically Complex Regression Errors
that were systematically extracted from the repositories and bug reports of four open-source software projects:
Make, Grep,
Findutils, and Coreutils.
These projects are well-tested, well-maintained, and widely-deployed open source programs for which the complete version history and all bug reports can be publicly accessed.
The test suites for all four projects provide about 8,000 test cases while further test cases can be generated as text input (command line) for the standardized
and specified program interfaces.
For each regression error, we determined the commit that introduced the error (),
the commit that fixed it (),
and a validating test case that passes () on the versions before the error
was introduced and after the error was fixed but fails ()
in between.
What do we know about it?
Through a systematic analysis of 4 x 1000 recent source code commits, we have
identified and validated 70 regression errors (incl. six segmentation faults)
that were introduced by 57 different commits.
Once introduced, 12% of the errors are fixed within a week while half stay
undetected and uncorrected for more than nine months up to 8.5 years.
Eleven errors were fixed incorrectly. In these cases the error was indeed
removed in the fixed version. Yet, up to three new errors were introduced that
required further fixes.
About one third of the errors were introduced by changes not to the program's
behavior but to non-functional properties such as performance, memory
consumption, or APIs.
In some cases one error would supercede
another error such that the latter was not observable for the duration
that the former remained unfixed. For instance, find.66c536bb
supercedes find.dbcb10e9.
Using CoREBench to study Error Complexity
Using CoREBench and our novel
error complexity metric, we can answer refined research questions, such as:
- What is the root-cause of a complex error? If an error requires a substantial fix, can we assume that
there is just one faulty statement causing the error? Are faults of complex errors localizable? The answers may
have implications for the performance of (statistical) debugging techniques.
- Test suite adequacy to expose complex errors?
Some widely used metrics of test suite adequacy, such as statement or branch coverage,
are based on the implicit assumption that errors are often simple, i.e., that
the fault is localizable within some branch or statement which is covered.
Now we may be able to investigate the effectiveness of coverage-adequate test suites w.r.t.
a varying degree of error complexity and may develop more sophisticated adequacy-criteria
that account for complex errors. Moreover, for the study of the relationship between
simple and complex errors (i.e., the coupling effect), we can take error complexity as
an ordinal rather than a dichotomous measure.
-
How do we repair complex errors? By definition, the fix of complex errors is
more substantial than for simple errors. The research community has made significant
progress understanding the automated repair of (simple) localizable errors.
Now we may be able to evaluate the efficiency of such repair techniques w.r.t. a
varying degree of complexity of the repaired errors.
Complex Regression Errors in CoREBench
Note that the version BEFORE the regression-introducing commit does not contain the error while the version AFTER the regression-introducing commit and BEFORE the regression-fixing commit does contain the error.
|
Download and Install CoREBench
* The Dockerfile, test scripts, and installation scripts are available on Github.
* Download and install Docker.
git clone https://github.com/mboehme/corebench.git
docker pull mboehme/corebench |  | |
docker pull mboehme/corebenchx |  |
./run.sh to start the Docker container with a shared directory /shared.
* Connect to the docker container
** Desktop. Install VNC and connect to <docker-ip>:5900 (password: corebench)
** Terminal. Execute ./run corebench to open container for find, grep, and make and ./run corebenchx for coreutils.
* Find scripts in directory /root/corebench and repository in /root/corerepo
* Implement analysis.sh as your analysis script
* Run ./executeTests.sh -test-all [core|find|grep|make|all] /root/corerepo
to execute for each error the test case,
1) on the version BEFORE the regression-INTRODUCING commit (should PASS)
2) on the version AFTER the regression-INTRODUCING commit (should FAIL)
3) on the version BEFORE the regression-FIXING commit (should FAIL)
4) on the version AFTER the regression-FIXING commit (should PASS)
Note: Use the folder /shared for scripts and other data you would like to maintain. All other data is lost in the event that the container is shut down. For instance, you can copy the folder /root/corebench to /shared, modify analysis.sh and execute ./executeTests.sh from /shared.
Download more Test Cases for CoREBench
* For debugging and repair, a much larger number of (auto-generated) test cases with oracles may be necessary.
* Such test cases are available on Github.
git clone https://github.com/thierry-tct/Tests_CPA_ICSE.git
* Credits: Titcheu Chekam Thierry, Mike Papadakis, Yves Le Traon and Mark Harman
* The authors note that the test case oracles were added manually, and the test cases are written for the patched versions.
* Read how these test cases were generated:
"Empirical Study on Mutation, Statement and Branch Coverage Fault Revelation that Avoids the Unreliable Clean Program Assumption", Titcheu Chekam Thierry, Mike Papadakis, Yves Le Traon and Mark Harman, in the Proceedings of the 39th International Conference on Software Engineering (ICSE'17), 2017.
Download Cyclomatic Change Complexity Tool
* Download: cycc.tar.gz:
Requires Linux environment, Git, OCaml, and CIL (see README.cycc).
* Run make
* Run ./csgconstruct --git <git-directory> --diff <diff-tool>
This will compute the Cyclomatic Change Complexity (CyCC) from the recent code commit in <git-directory>.
|