
|
This web page introduces the numerical algorithms that are frequently used to solve multimedia analysis problems. All of them can be found in Numerical Recipes in C. |
|
| 1. Solution of Linear Equations | |
|
A set of linear equations can be written in the matrix form A x = b where A is a m x n matrix of known coefficients, b is a m x 1 matrix (i.e., column vector) of known data, and x is a n x 1 vector of unknown variables.
E 2 = ||A x - b||2 . That is, perform linear least-squares fitting. |
|
| 2. Linear Least-Squares Method | |
|
We wish to fit a set of data points (xi , yi ) to a linear model such that yi = XT(xi ) a where X is a vector of known function and a is a vector of unknown parameters. Let's collect the yi into a vector b and the XT(xi ) into the rows of a matrix A. Then, we have A a = b . Least-square fitting looks for the a that minimizes E 2 = ||A a - b||2 This problem can be solved using singular value decomposition (SVD). The SVD of A is A = U diag(w1,..., wn) VT and x is given by a = V diag(1/w1,..., 1/wn) UT b i.e.,
where U( i ) and V( i ) are the ith column vectors of U and V. Note:
Least-squares fitting problem is also a minimization
problem, that is, to minimize the squared error E 2. a = (ATA)-1ATb . |
|
| 3. Nonlinear Least-Squares Method | |
|
When the model y(x; a) to be fitted depends nonlinearly on its parameters a, the Levenberg-Marquardt method can be applied. It combines both gradient (first derivative) method and Hessian (2nd derivative) method. |
|
| 4. Function Minimization and Maximization | |
|
Here, we are interested in minimizing a function f(x) of multidimensional variable x. The simplest method called gradient descent or steepest descent starts off with x equal to some initial value P(0) and updates P(i) according to the negative gradient of f(P(i)):
where h is a constant update rate. This method is usually not very good except for simple problems. But, it is a simple method. Another method is to apply Powell's direction set method. It will estimate the gradient using the f supplied by the user, and so does not require the user to supply the gradient information. Two other families of methods require the user to supply the gradient information. The first family of methods is known as the conjugate gradient methods, and the second family is the variable metric or quasi-Newton methods. Note: Most optimization algorithms require a good guess for the initial P. The nearer the initial P is to the optimal P, the faster the algorithms converge, and the more accurate is the result. |
|
| 5. Eigensystems | |
|
Given a real, symmetric n x n matrix A, there exist vectors vi and scalar values li such that A vi = li vi . The vectors vi are called the eigenvectors and the scalars li the corresponding eigenvalues of the matrix A. There are many implementations of eigen-decomposition, including one in Numerical Recipes in C. |
|
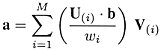
Last updated: 15 Dec 2004