MLCask Overview
Project MLCask: Efficient Management of Component Evolution in Collaborative Data Analytics Pipelines
Overview
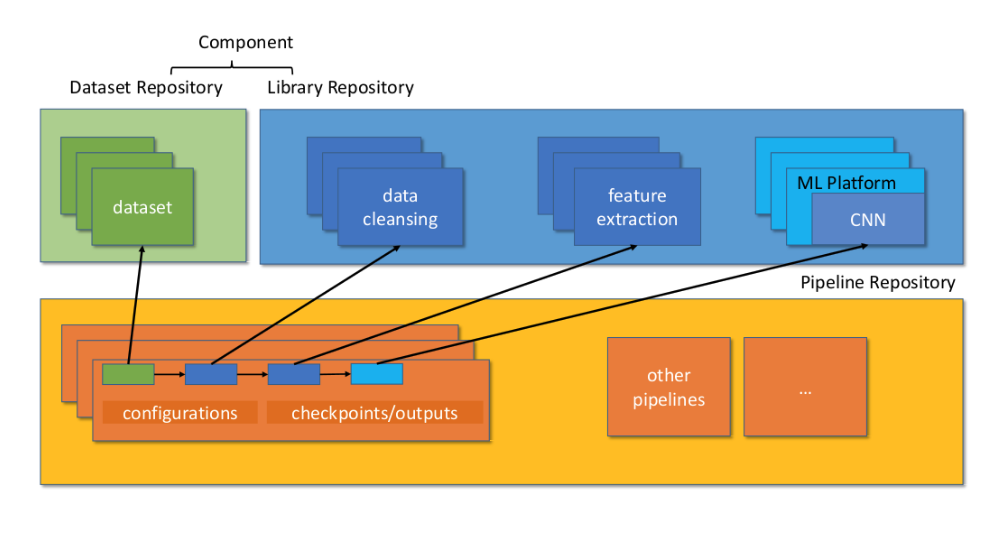
The system architecture of MLCASK is illustrated above. In general, we abstract an ML life-cycle with two key concepts: component and pipeline.
A component refers to any computational units in the ML pipeline, including datasets, pre-processing methods, and ML models. In particular, we refer library to either a pre-processing method or an ML model. A dataset contains a mandatory metafile and a series of optional data files. A library consists of a mandatory metafile and several executables. A pipeline is the minimal unit that represents an ML task. A pipeline metafile describes the entry point of the pipeline and the order of the pipeline components.
Considering that a single dataset or library may be used by multiple pipelines, we design a dataset repository and a library repository to store different versions of datasets and libraries respectively. A pipeline repository is also introduced to record the version updates of all the pipelines.
Example Pipeline: Let us exemplify an ML pipeline, as shown in the figure, which consists of datasets, data cleansing, feature extraction, and a convolutional neural network (CNN) model. This ML pipeline is used to predict whether a patient will be readmitted into the hospital within 30 days after discharge.