(Adapted from Peter Heeman's homework for his Spoken Language Systems course).
Homework #2 - Bottom-up and Chart parsing
You should submit your working version of the parsers and your
answers to the discussion questions by the midnight on the due date.
The IVLE workbin will accept late submissions. Late submissions are
subject the the late submission policy
(read carefully). Your submission should contain a plain .txt file
called students.txt which
should have the same format as given in the hyperlink (in fact, why
don't you save the linked file now and adapt it before you submit
it?). Store your answers to the written questions in a file called
answers.txt (N.B. Make sure your files are in plain
ASCII text format -- MS Word files or other word processing files will
not be entertained). Your team's work should be done independently of
other groups; see our classes' section on Academic Honesty Policy if you have
questions about what that entails.
Bottom-up parsing
First you are going to build a bottom up parser. To start you off, I'm giving you the pseudocode for the parsing algorithm and the grammar that you will need to parse. Here is a sample grammar that you will need to take as input, along with a test sentence. You'll need to read this file in as input to your parse command. It can vary in the number of rules and the elements for each rule, but basically you'll have a NONTERMINAL as the first element of the rule, followed by an arrow ('->') and then one or more NONTERMINAL and/or terminal symbols as the remaining elements. NONTERMINALS are in ALL CAPS whereas terminals are always in lowercase. We can read a rule like
VP -> V NP
as VP can be replaced by the non-terminal sequence "V NP". V and NP would have to be expanded in later iterations, (hopefully) progressing towards the replacement of all NONTERMINAL symbols by terminal ones. Note that terminals cannot appear as the first element in a rule (else they would not be terminal symbols!). The special NONTERMINAL symbol 'S' denotes the start symbol (in our case it represents a sentence).
Here's the psuedocode for the bottom-up parser:
Add word sequence to list of alternatives
While list of alternatives is not empty
Pull out first alternative from list
For each rule
For each token in sequence
If rule can be applied ending at that token
Rewrite sequence with rule
If new sequence is start symbol
Add to a list of solutions
Otherwise
Store new sequence at end of list of alternatives
This is a bottom-up parser as it starts from the terminals and
tries to work its way back towards the start symbol. A top-down
parser works in reverse, by starting from the start symbol and trying
to find a sequence of rules that will eventually rewrite to form the
input text. Your group's code should be in a single class file called
BottomUpParser.java. The output of the
system when invoked should be a parse tree in parenthetical form
(e.g., (S (NP (PRONOUN you) (VP (VP (VP (V give) (NP (PRONOUN
me))) (NP (ARTICLE the) (N gold))))). There will be no empty
rules or recursive rules where the left hand side NONTERMINAL exactly
matches the right hand side non-terminals (e.g., no rules like A -> ""
or A -> A.
Questions for your group to answer and put in the
answers.txt file.
- For the sample test case, how many parses were returned?
- How many times was the code corresponding to "Store new sequence at end of list of alternatives" executed?
- What type of search algorithm does this parser correspond to?
Chart parsing
Now you are going to build a chart parser, which is much more efficient than the bottom up parser you implemented earlier. Chart parsing works by using dynamic programming; using and storing the solutions of smaller parts of sentence to solve larger problems. In contrast to the above parser which only invokes a rule if all the constituents in the right hand side (RHS) are present, chart parsing works incrementally, word by word. Consider a rule "A -> B C D". If the parser sees "B", it starts to apply this rule. Rather than rewriting B with A, we rewrite it with "A -> B . C D", where the period indicates how far in the rule we've gotten. If later, we see C after B, we can continue and rewrite the rule as "A -> B C . D". This is a called a "shift". Once D is seen, we are finished with the rule and we can rewrite it as in the earlier parser, and replace it with just "A". This is a called a "reduce" move.
A chart parser keeps track of what it has parsed by using edges. Each edge is a data structure with the following fields:
- head - the NONTERMINAL which is the left hand side of the rule (LHS)
- done - the constituents in the body of the rule that have been processed (the ones to the left of the period.
- rest - the constituents left to match, to the right side of the period.
- start - the index of the first word accounted for in done.
- end - 1 + index of the last word accounted for in done.
Each word in the input sentence is treated as an unit edge. For example in the sample sentence "time flies like an arrow", the first word "time" would be represented as an edge with values:
| head | time |
| done | time |
| rest | |
| start | 0 |
| end | 1 |
The parsing process takes these initial edges and gradually grows them into larger and larger edges, progressing towards the start state, as in the bottom-up parser. A new edge can be created from the joining of two edges:
|
+ |
|
=> |
|
A new edge also needs to be created from the satisfaction of the initial shift in a grammar rule:
|
+ |
|
=> |
|
You can trace the progression of the chart parser on this diamond graph. For each diamond, fill in the rules that can be applied using notation head -> done.rest. For diamond i-j the rules will be those with start at i and end at j.
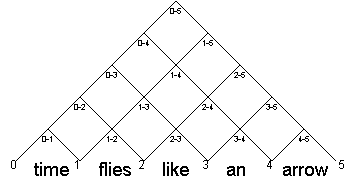
A chart parser has a certain way of working its way through the edges that need to be added to the chart. All edges that are created are put in the chart, but a subset of these form an agenda. The agenda keeps track of edges that need to be processed to build new edges. Edges that have an empty (null-valued) rest field are such candidates for future work. These edges are put on the agenda. We process the agenda items, one by one, to create new edges by the Edge+Edge rule or by the Grammar+Edge rule.
Your group is the implement a chart parser using the same initial grammar. The psuedocode for the chart parser is below:
for each word
add an edge to the agenda for the word
while agenda not empty
take top edge off agenda, call it e
// Grammar+Edge Rule
for each rule whose first constituent starts with e's head
add a new edge
// Edge+Edge Rule
for each edge c in the chart
if c's end time matches up with e's start time AND
the first constituent of c's rest line is e's head
add a new edge
Implement the chart parser in a java class called
ChartParser.java. It should accept the same command line
syntax as the previous Bottom-Up parser, reading in a grammar file and
a test sentence file, and outputting a list of valid parses.
Also, you'll need to take ten sentences (we suggest five of them to
be the ones in the midterm lecture, slide 11) and
create plausible grammar rules to be able to parse them. Each word in
any of the sentences should have all of its possible parts-of-speech
listed in the production rules (e.g., if you put in the word
"bank" it should be listed both as a V and as a N). You can
use a dictionary to look up a word's acceptable parts of speech. Using
the time command on sunfire, time the command when given
to your Chart Parser and your Bottom Up parser. Discuss the
efficiency of both algorithms. You can place the answers to these
questions in the answers.txt file.
Min-Yen Kan <kanmy@comp.nus.edu.sg> Created on: Mon Dec 1 19:36:22 2003 | Version: 1.0 | Last modified: Thu Mar 18 09:32:07 2004