

17 Sep 2003
CS 6210 – Module 6
22
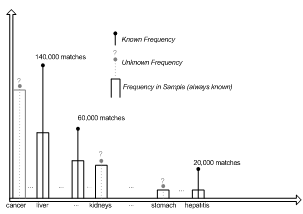
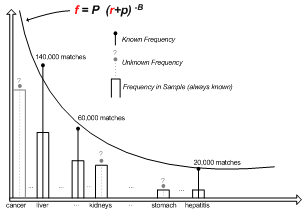
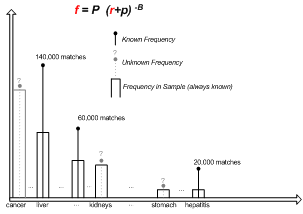


Adjusting Document Frequencies
¡We know ranking r of words according to document frequency in sample
¡We know absolute document frequency f of some
words from one-word queries
¡Mandelbrot’s formula connects
empirically word
frequency f and ranking r
¡We use curve-fitting to estimate the absolute frequency of all words in sample
r
f