|
1
|
|
|
2
|
- Optimal decisions
- α-β pruning
- Imperfect, real-time decisions
|
|
3
|
- “Unpredictable” opponent à
specifying a move for every possible opponent reply
- Time limits à unlikely to
find goal, must approximate
- Hmm: Is hex a game or a search problem by this definition?
|
|
4
|
|
|
5
|
|
|
6
|
- Several piles of sticks are given. We represent the configuration of
the piles by a monotone sequence of integers, such as (1,3,5). A player
may remove, in one turn, any number of sticks from one pile. Thus,
(1,3,5) would become (1,1,3) if the player were to remove 4 sticks from
the last pile. The player who takes the last stick loses.
- Represent the NIM game (1, 2, 2) as a game tree.
|
|
7
|
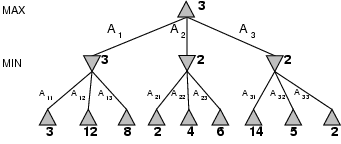
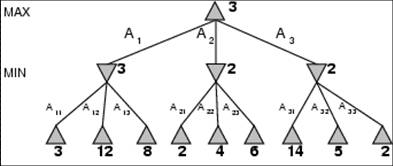
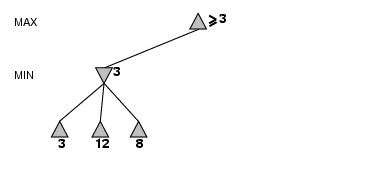
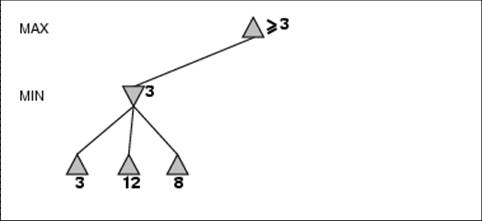
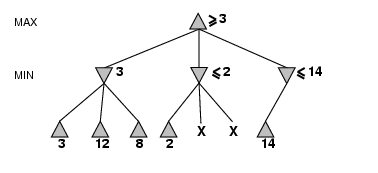
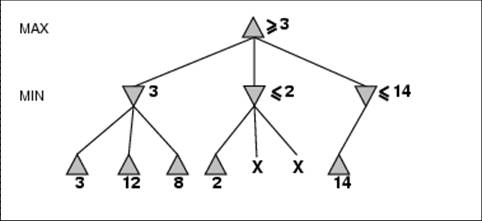
- Perfect play for deterministic games
- Idea: choose move to position with highest minimax value
= best achievable payoff against best play
- E.g., 2-ply game:
|
|
8
|
|
|
9
|
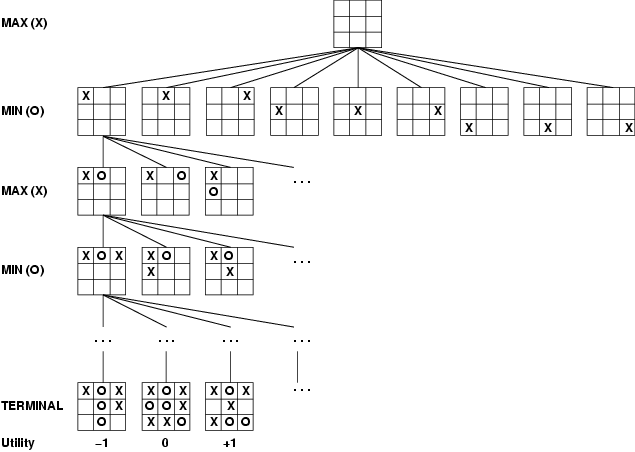
- Complete? Yes (if tree is finite)
- Optimal? Yes (against an optimal opponent)
- Time complexity? O(bm)
- Space complexity? O(bm) (depth-first exploration)
- For chess, b ≈ 35, m ≈ 100 for “reasonable” games
à exact solution
completely infeasible
- What can we do?
- Pruning!
|
|
10
|
|
|
11
|
|
|
12
|
|
|
13
|
|
|
14
|
|
|
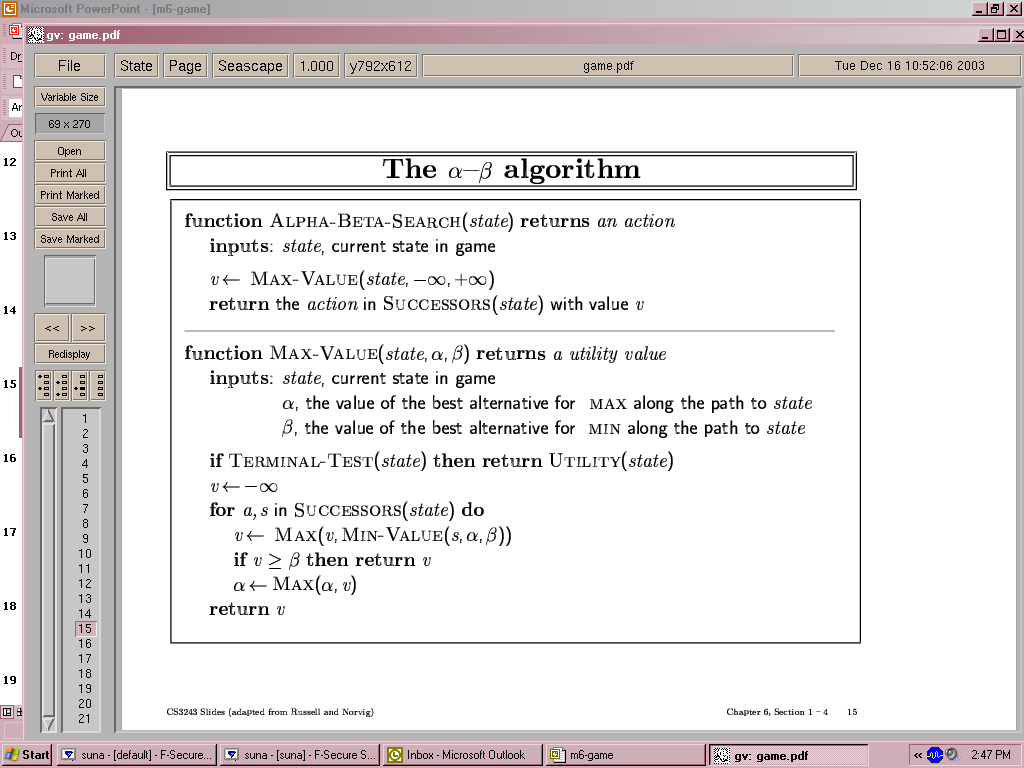
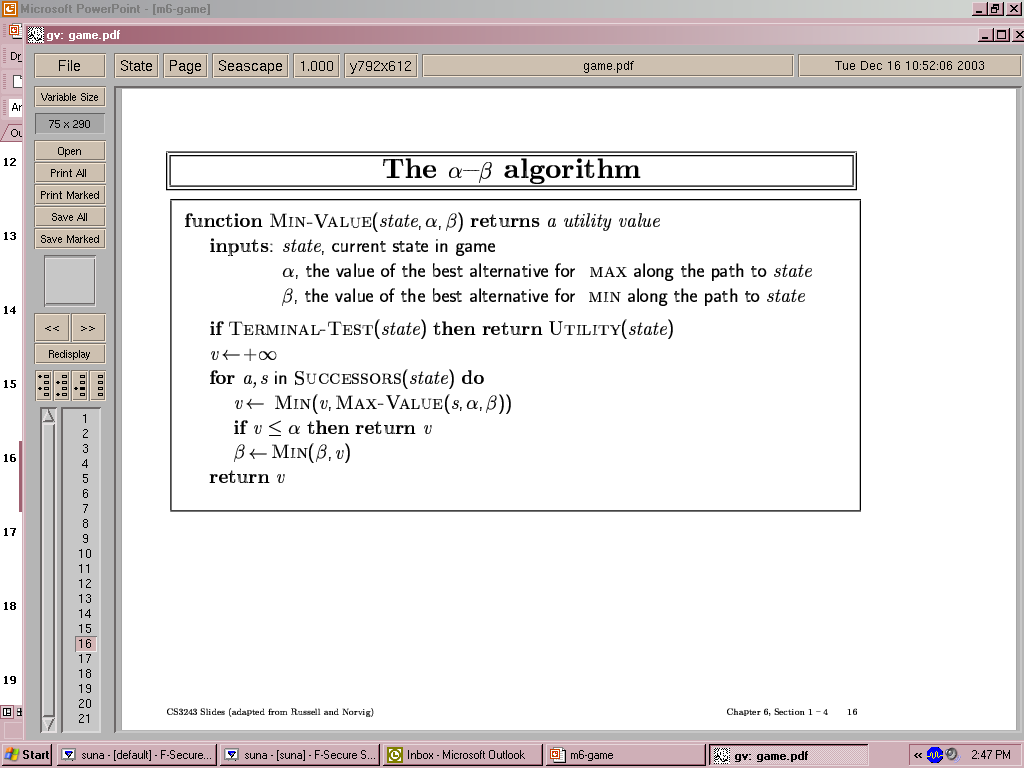
15
|
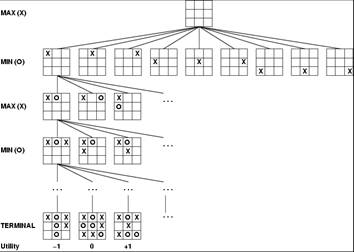
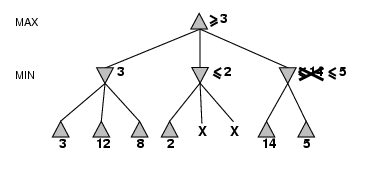
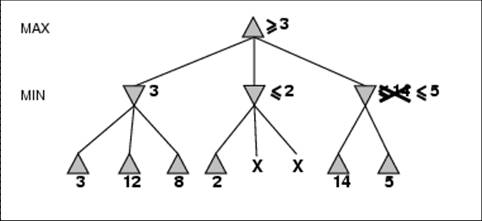
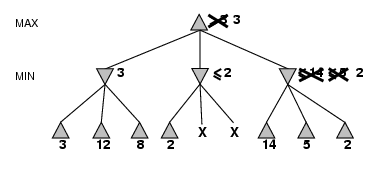
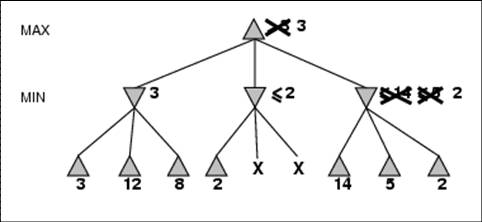
- Pruning does not affect final result
- Good move ordering improves effectiveness of pruning
- With “perfect ordering”, time complexity = O(bm/2)
- à doubles depth of search
- What’s the worse and average case time complexity?
- Does it make sense then to have good heuristics for which nodes to
expand first?
- A simple example of the value of reasoning about which computations are
relevant (a form of metareasoning)
|
|
16
|
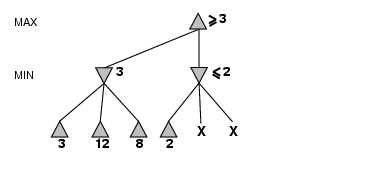
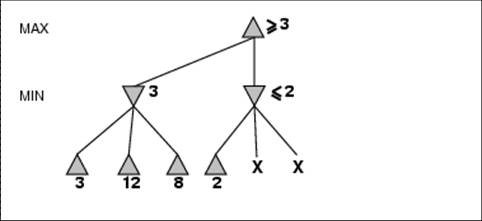
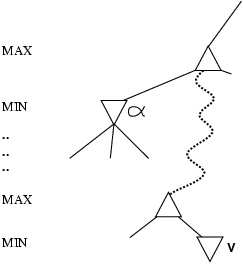
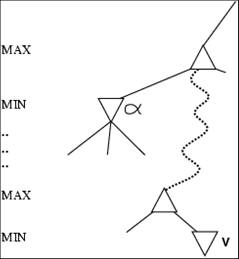
- α is the value of the best (i.e., highest-value) choice found so
far at any choice point along the path for max
- If v is worse than α, max will avoid it
- Define β similarly for min
|
|
17
|
|
|
18
|
|
|
19
|
- The big problem is that the search space in typical games is very large.
- Suppose we have 100 secs, explore 104 nodes/sec
à 106 nodes
per move
- Standard approach:
- cutoff test:
- e.g., depth limit (perhaps add quiescence search)
- evaluation function
- = estimated desirability of position
|
|
20
|
- For chess, typically linear weighted sum of features
- Eval(s) = w1 f1(s) + w2 f2(s)
+ … + wn fn(s)
- e.g., w1 = 9 with
- f1(s) = (number of white queens) – (number of black queens), etc.
- Caveat: assumes independence of the features
- Bishops in chess better at endgame
- Unmoved king and rook needed for castling
- Should model the expected utility value states with the same feature
values lead to.
|
|
21
|
- A utility value may map to many states, each of which may lead to
different terminal states
- Want utility values to model likelihood of better utility states.
|
|
22
|
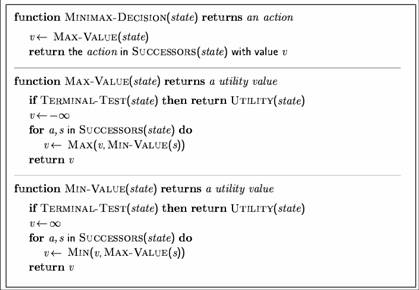
- MinimaxCutoff is identical to MinimaxValue except
- Terminal? is replaced by Cutoff?
- Utility is replaced by Eval
- Does it work in practice?
- bm = 106, b=35 à m=4
- 4-ply lookahead is a hopeless chess player!
- 4-ply ≈ human novice
- 8-ply ≈ typical PC, human master
- 12-ply ≈ Deep Blue, Kasparov
|
|
23
|
- Checkers: Chinook ended 40-year-reign of human world champion Marion
Tinsley in 1994. Used a precomputed endgame database defining perfect
play for all positions involving 8 or fewer pieces on the board, a total
of 444 billion positions.
- Chess: Deep Blue defeated human world champion Garry Kasparov in a
six-game match in 1997. Deep Blue searches 200 million positions per
second, uses very sophisticated evaluation, and undisclosed methods for
extending some lines of search up to 40 ply.
- Othello: human champions refuse to compete against computers, who are
too good.
- Go: human champions refuse to compete against computers, who are too
bad. In go, b > 300, so most programs use pattern knowledge bases to
suggest plausible moves.
|
|
24
|
- Games are fun to work on!
- They illustrate several important points about AI
- Perfection is unattainable à must approximate
- Good idea to think about what to think about
|
|
25
|
- What does the web page say?
- http://www.comp.nus.edu.sg/~cs3243/
|
|
26
|
- Implement Minimax
- Implement Pruning (optional)
- Implement an evaluation function
- Input: board, selected grid location
- Output: continuous value
- (really optional) use state
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}