|
1
|
- Bang V. NGUYEN and Min-Yen KAN
- Department of Computer Science
- School of Computing
- National University of Singapore
|
|
2
|
- aloha airlines
- color blindness
- kazaa lite
- house document
no. 587
- What can we see?
- Different types of queries!
|
|
3
|
- Theory: earlier Classifications
(Broder, 2000; Rose and Levinson, 2004)
- Originally to uncover latent user intent
- Largely mutually exclusive
- Practice: Automated classification
- Kang and Kim (2003)
- Lee et al. (2004)
- and others …
- A clear mismatch between theory and practice
|
|
4
|
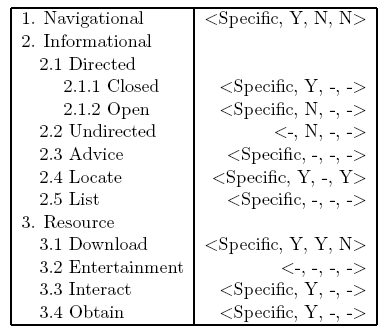
- Functional: meaning that an automated engine can use the results to act
appropriately
- Faceted: meaning that queries can manifest different, fine grained
behavior in combination
- Mostly independent facets
|
|
5
|
- How to formulate such a classification scheme?
- How does such a classification relate to previous work?
- How are web queries distributed given this scheme?
- How well do human subjects classify against this scheme?
- Just briefly: how to automate such a classification?
|
|
6
|
- Goals of the classification:
- Should have high coverage
- Have discrete values
- For ease of replication and analysis
- Facets should be largely independent
- Different combinations of facets possible
- Classification leads to action
- Went through several iterations, settled on four facets
- Others considered but dropped
|
|
7
|
- Ambiguity = Specific
- Authority sensitive? = Yes
- Temporally sensitive? = No
- Spatially sensitive? = No
- Most facets have been proposed before by others
- We integrate them into one classification scheme
- Let’s look at each facet in more detail
|
|
8
|
- Modeled after a library agent’s interpretation of ambiguity (Stojanovic,
2005)
- Actionable strategies:
- Disambiguation / Categorization
- Suggest modifiers for general queries
- Examples:
- Polysemous: contain many senses
- General: cover multiple sub-categories
- Specific: address a coherent set of relevant information
|
|
9
|
- Does the query refer to a well-known concept or an authoritative answer?
- Actionable strategies:
- Jump directly to or extract
authoritative results
- Favor prestige factors (e.g. PageRank) in ranking results
- Examples
- Yes
- “hsbc internet banking”
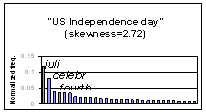
- “U.S. independence day”
- No
- “laptop harddrives”
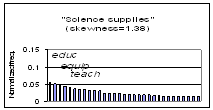
- “science supplies”
|
|
10
|
- Should the query results change with respect to the user’s temporal or
spatial context?
- Lots of related work; just a sample:
- Categorizing web queries according to geographical locality (Gravano et
al , 2003)
- Information diffusion through blogspace (Gruhl et al, WWW ‘04)
- Temporal relation between queries (Chien et al , WWW ‘05)
- Actionable strategies:
- Suggest temporal or spatial modifiers
- Make users aware of spatially / temporally changing
- Take locality of users into account
- Temporal Examples
- Yes
- “university ranking”,
“u.s. president”
- No
- “Toyota Canada”,
“gravity forces”
- Spatial Examples
- Yes
- “transport services”,
“pizza order”
- No
- “email signature”,
“how to run fast”
|
|
11
|
- How to formulate such a classification scheme?
- 1. How does such a classification relate to previous work?
- 2. How are web queries distributed given this scheme?
- 3. How well do human subjects classify against this scheme?
- Just briefly: how to automate such a classification?
|
|
12
|
- Observations:
- Previous work only dealt with specific queries
- Previous work often not actionably differentiated – have same facet
signature
|
|
13
|
- Manual classification
- 100 queries (limited, small indicative sample)
- Randomly chosen
- Reject non-English, offensive queries
- From AllTheWebTM, 2002
- Judged by authors
- Use only the query string and search results as evidence
- Other data (e.g., clickthrough data) intentionally left out
|
|
14
|
- Specific queries make up a majority.
- Almost half of require authoritativeness
- Temporally and spatially sensitive queries amount to about 1/5th.
- Percentage growing with mobile devices?
|
|
15
|
- Subsampled 75 of the 100 queries
- Asked 25 human volunteers to judge queries
- Each query is judged by 5 evaluators.
- Capture the average rating of all users on each facet on Likert 5-point
scale
- (1 sensitive, 5 insensitive)
- (1 specific, 5 ambiguous)
- Goals:
- A. Is our classification replicatable / understandable?
- B. Are the coarse granularity of facet values ok?
|
|
16
|
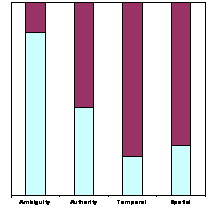
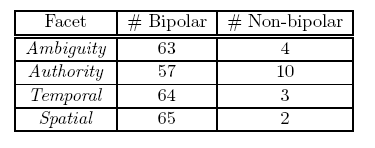
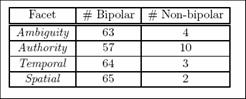
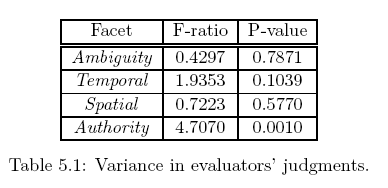
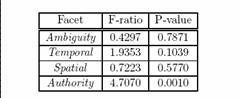
- ANOVA: do people agree?
- P-value > .01 people do not differ significantly
- Conclude:
- Ambiguity, Temporal and Spatial Sensitivity OK
- Authority needs work, not consistent
- Bipolar (1 or 5) vs.
Non-bipolar (2, 3 or 4)
- Conclude:
- Subjects satisfied with coarse grained values
- Validates our value choices
|
|
17
|
- How to formulate such a classification scheme?
- 1. How does such a classification relate to previous work?
- 2. How are web queries distributed given this scheme?
- 3. How well do human subjects classify against this scheme?
- Just briefly: how to automate such a classification?
|
|
18
|
- Most facets already have prior work for automated classification
- Ambiguity:
- Analyzing content topical distribution; lexical databases
- Temporal and spatial sensitivity: mining of query log to find temporal
modifiers
- “U.S. president” and “U.S. president 1966
- measure changing results via content publishing (e.g. RSS)
- However, authority sensitivity has not yet been explored
|
|
19
|
- Hypothesis: authoritative queries often have answers repeated in search
results
- Idea: Look for repeating information
(c.f., trusted question answering)
- Examine summary snippets for query
- Extract keywords and measure their distribution
- Capture keyword histogram’s skewness:
|
|
20
|
- Use just this one feature
- Learn a classification boundary
- 78%, 60%, 68% for Precision, Recall, F1
- Conclude (Indicative)
- Automatic classification is possible for authority sensitivity
|
|
21
|
- Proposed a faceted actionable scheme with four facets:
- Ambiguity, Authority, Temporal and Spatial Sensitivity
- Related our classification to previous work
- Showed reliability: authority facet perhaps not well defined
- Gave indicative distribution based on small query set
- Future work:
- Implement a fully automated classification system
- Larger scale evaluation and distributional analysis
- Investigate possible expansion of the taxonomy
- Requirement for special collection?
|
|
22
|
- Tuesday, May 8
- Location: Beatty?
- 25 minute slot?
- 20 minute talk
- 2 Motivation
- 8 Facets
- 7 RQ
- 2 Automated
- 1 Conclusion
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
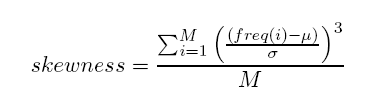{kind=link}
{kind=link}