|
1
|
- Shi-Yong Neo, Jin Zhao, Min-Yen Kan, and
- Tat-Seng Chua
- School of Computing
- National University of Singapore
|
|
2
|
- Problems in news video retrieval
- Primary source of semantics come from ASR, but ASR tends to be
erroneous & non-grammatical
- Text does not necessarily relate well to visual information
- Low-level features are unreliable and unpredictable
- What we have:
- Annotation of relevant high-level features (HLFs) with varying accuracy
- Question: How to capitalize these HLF’s to support retrieval?
|
|
3
|
- Low-level features (color, edge, texture…):
- tend to be unstable and unreliable in representing semantics
- Also, hard to relate a query to suitable low level features
- For example: “Find shots with people holding banner”
- High-level features
- Detectors of varying accuracy are available. For example, face, car,
boat, commercial, sports, etc
- Provide partial semantics to ASR and queries
- Have been shown to be effective in TRECVID 2005
- Can be easily incorporated into text-based retrieval systems
|
|
4
|
- The 10 available high level visual features
- Sports, Car, Walking, Prisoner, Explosion
- Maps, US-flag, Building, Waterscape, Mountain
|
|
5
|
- Query matching:
- Problem: How to automatically associate HLFs to queries for use in
effective retrieval?
- Approach:
- Identify visual-oriented descriptions in HLFs w.r.t. query
- Investigate time-dependent correlation between HLFs
- Confidence-based Weighting:
- Problem: HLF detectors vary greatly in performance
- Approach: Introduce performance-weighted framework that accounts for
confidence of individual detectors
|
|
6
|
- Review some related work done in TRECVID 2005
- IBM group
- Automatically map query text to HLF models
- Weights are derived by co-occurrence statistics between ASR texts and
detected HLFs
- Columbia group
- Match text queries and sub-shots in an intermediate concept space
- Sub-shots are represented by outputs of concept detectors
- Text queries are mapped into the concept space by measuring their
semantic similarity
- Amsterdam, CMU and many others also utilize HLFs in their retrieval
systems
|
|
7
|
- Query Matching
- Time-Dependent Similarity Measure
- Confidence-based fusion
- Evaluation Results
- Conclusions
|
|
8
|
- Both query and text descriptors for HLFs are short
- Question: how to expand query and relate query to relevant HLFs?
- Utilize WordNet to perform expansion of both:
- Use synonym, hypernym and hyponym as usual
- Use also terms from WordNet glosses, which provides visual information
about an object -- its shape, color, nature and texture
- Example:
- From WordNet hierarchy: Boat à “is-a kind of vessel”
- From WordNet gloss: Boat à “a small vessel for travel on water”
- è able to relate boat to “travel
on water”
|
|
9
|
- Pre-processing of queries
- Q0 à Q1
by performing query expansion using external info
- Q1 à Q2
by WordNet expansion
- Pre-processing of HLFs
- HLFi0 à HLFi1:
by Wordnet expansion
- Relevance between query and HLFs is determined as:
- Sim (Q2, HLPi1)
- Able to relate concept boat to query about “water”
|
|
10
|
- More specifically, employ the information-content metric of Resnik to
relate Q2 to HLFi1
- Resnik(ti, tj) = IC(lcs(ti, tj))
- where lcs(ti, tj) is the most deeply nested
concept in the is-a hierarchy
- The resulting query is:
|
|
11
|
- Query Matching
- Time-Dependent Similarity Measure
- Confidence-based fusion
- Evaluation Results
- Conclusions
|
|
12
|
- In relating Q2 to relevant HLFi1, how to reduce
the noise introduced by the dictionaries, esp, the gloss?
- Several sources of noise:
- Typical examples
- {Story 1: Forest fire},
- {Story 2: Explosion and bombing},
- {Story 3: Bombing and Fire}
- Fire à found in stories
1, 2, 3
- Explosion à found in
stories 2, 3 (but 1 may be retrieved as fire is closely related to
explosion)
- {car, boat, aircraft}
- Related via modes of transportation (similar nature)
- But we cannot use the concept car to find concept boat…
|
|
13
|
- Use time-dependent co-occurrence relationships between HLFs in parallel
corpus to relate them
- fire + explosion
- Time period t1 à high
- Time period t2 à low
- car + plane
- car + boat
|
|
14
|
- Query Matching
- Time-Dependent Similarity Measure
- Confidence-based fusion
- Evaluation Results
- Conclusions
|
|
15
|
- Different HLFs have different prediction confidence
- Need to take this into consideration
- Obtain the confidence info from the available training samples to
perform 5-fold cross validation
|
|
16
|
- Query Matching
- Time-Dependent Similarity Measure
- Confidence-based fusion
- Evaluation Results
- Conclusions
|
|
17
|
- Test on real human subjects
- 12 paid volunteers were asked to assess how they would weight HLFs
- Based on 8 TRECVID 2005 queries selected
- Ask users to freely associate what types of HLFs would be important in
retrieving such video clips
- ..and to assign the importance (on a scale from 1-5) of the specific
HLF inventory set used
|
|
18
|
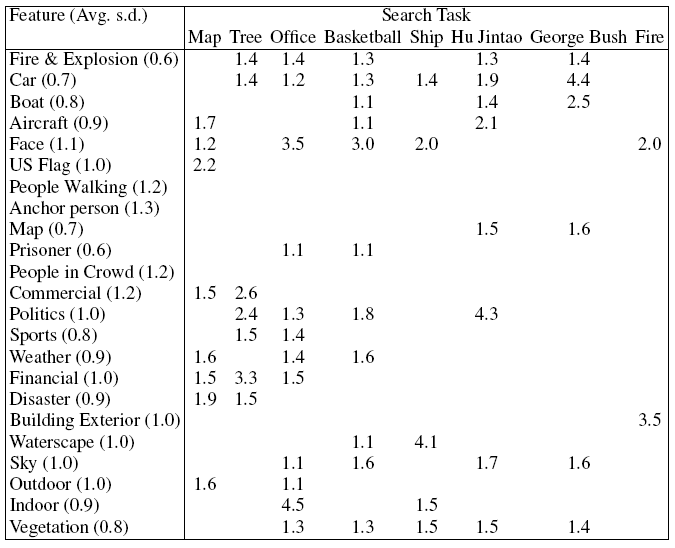
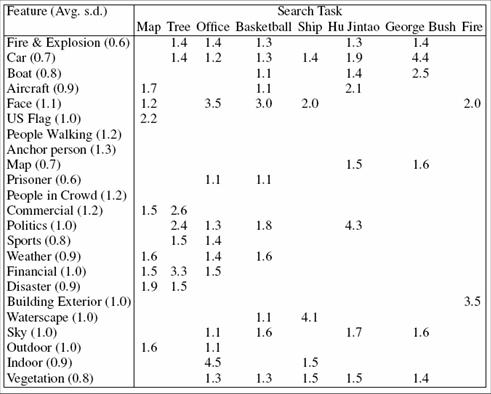
- Inter-judge agreement using Kappa is low ( 0.2 to 0.4)
- Ratings for concrete nouns were most stable, follow by backgrounds and
video categories, with actions being the worse
- Negative correlations are prominent in our dataset
|
|
19
|
- Further test compares Kappa scores of HLF rankings by system and by
human subjects
- Rating is again low
- Reason: WordNet expansion works well for hypernym and hyponym only, but
not for other relations
- To investigate this problem further
|
|
20
|
- Effect of query matching
- Standards set by TRECVID 2005 automated search task
- 24 queries
- Return a rank-list of up to 1000 shots
- Performance measured in Mean Average Precision (MAP)
|
|
21
|
- Baseline: pervious TRECVID 2005 system that uses heuristic weights to
link query and HLFs
- Run1: Baseline + query matching without WordNet glosses
- Run2: Run1 + WordNet glosses
- Run3: Run2 + time-dependent similarity measure
|
|
22
|
- Run4: Run3 and Run3+confidence-based fusion
- Run5: Run4 + other A/V features
used in our TRECVID run. It is designed is designed to investigate the
overall performance of the system w.r.t. typical TRECVID systems
|
|
23
|
- Features used at each unit:
- Low level features
- High level features
- ASR
- Video OCR
- Face Detection & Recognition
- Shot Genres
- Audio Genre
- Story boundaries
- High-level Visual Concepts
|
|
24
|
- Run4: Run3 and Run3+confidence-based fusion
- Run5: Run4 + other A/V features
used in our TRECVID run. It is designed is designed to investigate the
overall performance of the system w.r.t. other TRECVID systems
|
|
25
|
- Run1 and Run2 indicates that the use of WordNet glosses is positive
- Run3, which adds in time-dependent similarity measure, obtain a MAP of
0.113 which is an improvement of 8.6%
- Run4 demonstrates the effectiveness of confidence-based weighting
- The bulk of improvement come from general queries as they depend largely
on the use of HLFs as evidence of relevance
- Person-oriented queries on the other hand have less significant
improvement as ASR and video OCR still contribute most to the overall
score
|
|
26
|
- Query Matching
- Time-Dependent Similarity Measure
- Confidence-based fusion
- Evaluation Results
- Conclusions
|
|
27
|
- Explore two approaches to extend the framework of multi-modal news video
retrieval systems
- Overall, our new Text + HLF retrieval system is able to
- Outperform baseline system
- Achieve similar results to top performing automated systems reported in
TRECVID 2005
- When integrating with other A/V features, the resulting performance is
better than the best reported result.
- Current Work
- Investigate better ways to link HLFs to queries or general concepts
- Better correlations between HLFs
- Link to event-based models
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
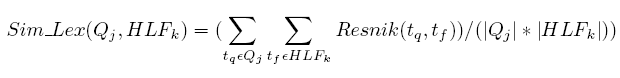{kind=link}
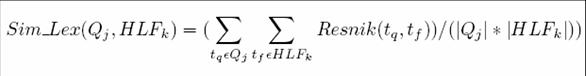{kind=link}
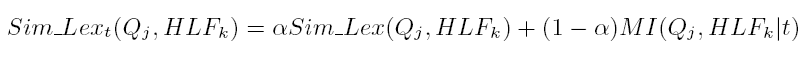{kind=link}
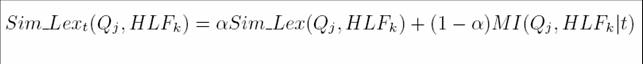{kind=link}
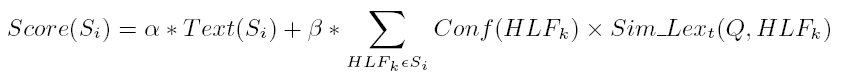{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}