GSoC 2019 Project: Extending Chainer compiler to support python jump syntax
![]()
Chainer is a popular and relatively nascent ML framework that uses a define-by-run architecture. Unlike Tensorflow, the intermediate computation graph representation in Chainer is not defined before computation begins but is dynamically generated, thus allowing considerably more flexibility. The API for Chainer offers a better abstraction over the IR generation by enabling python syntax such as if-else and for in generation as opposed to Tensorflow which requires constructs like tf.cond and tf.while_loop for control flow and iteration. There are some subtle but useful advantages of using Chainer framework which makes rapid prototyping and testing really simple. For instance, since the computation graph is defined while execution, the variables involved store the history of computation that resulted in their values (which is used during backprop). This allows debugging a model really simple as you can directly probe the gradients being computed.
With all these benefits, Chainer is definitely an attractive ML framework, but Tensoflow’s define-and-run emerges as the champion when it comes to deep learning research and industry. In the research field, the primary reason in favor of Tensoflow is that the direct control of computation graph definition enables unforeseen use cases, like engineering a non trivial neural-net architecture (say GAN) for the fist time. In industry also, where the models run in production, changes in the computation graph can be monitored reliably and easily in Tensorflow thanks to it’s really handy Tensorboard. Also, a static and shippable computation graph IR is desireable in any ML framework due to growing use of AI in mobile apps and browser extensions.
![]()
Open Network Neural Exchange is an impressive effort to standardize the intermediate representation for several ML frameworks, bridging the gap between them by allowing interchangeability, e.g. tensorflow-onnx, torch.onnx, etc. A direct consequence of this effort has resulted in development of interesting applications such as ONNX.js (a Javascript library for running ONNX models on browsers and on Node.js), onnxruntime (a cross-platform scoring engine for onnx models) and YOLOv3 (an iOS app that uses onnx for shipping pre-trained image recognition models).


Tensoflow has IR very similar to ONNX Tensorflow IR) and therefore interconnection is pretty straightforward. PyTorch on the other hand uses a just-in-time (JIT) compilation that converts the python code into it’s own internal representation computation graph. As ONNX is becoming an industry standard, there is a need to onboard Chainer framework too, which is the goal of Chainer Compiler. Unlike other ML frameworks however, this compiler doesn’t use the Intermediate IR (probably because the IR is dynamic and is defined only while execution of the model). Instead, it extracts the python abstract syntax tree (using gast) of the model’s user defined functions (including forward and __init__) and translates it into ONNX computation graph by recursion over the AST nodes. While this seems like a super long and difficult process to design, it comes with benefits. For instance, operations on data types such as numpy and python list which, unlike Chainer `Variable’, doesn’t store the history of operations can also be backproped over. This is because while parsing the AST, we can generate appropriate nodes for them in the computation graph even though they are not part of Chainer’s links and functions. Plus, the computation graph generated like this is not restricted to constructs that support backprop operations. Pre/post processing steps, optimizers, etc., which don’t have an internal representation in Chainer can also be translated into ONNX by this approach.
The approach followed by Elichika for ONNX translation is being explained in the flowchart below (not the official design). The compiler is passed a Chainer model of base type chainer.Chain, which contains the user defined logic for model computation. After loading the mappings for different Chainer links and functions as well as numpy functions to computation nodes generators, the compiler starts the translation by extracting the AST from the passed model’s constructor and user defined functions. Starting from the AST of the forward function, the recursive translation to an internal intermediate representation called ONNXGraph (not ONNX) is performed. This intermediate representation abstracts out the exact circuit of ONNX compute nodes required for a relatively higher level operation, such as looping or conditional statements.
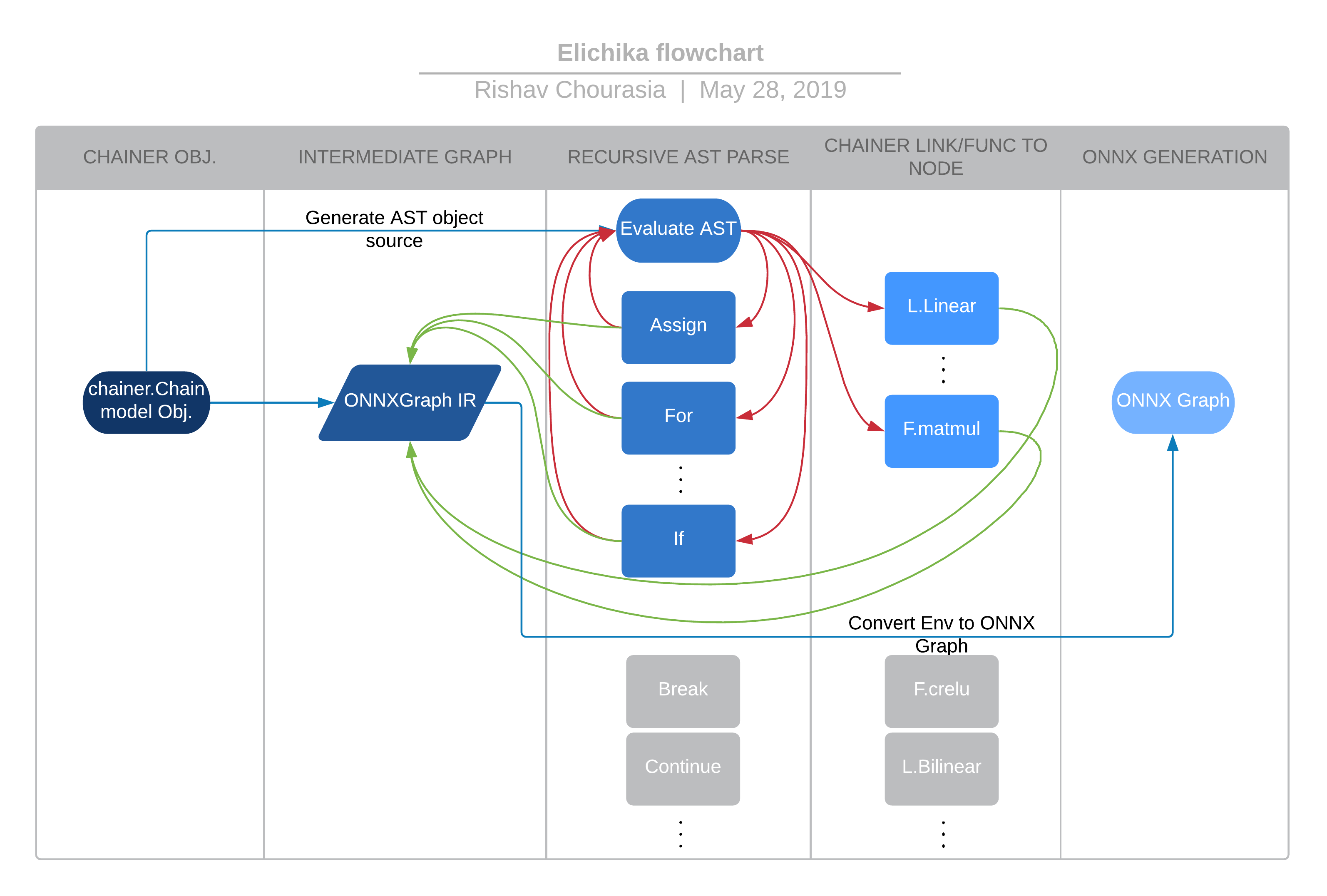
How does the translation happen?
The basic idea is that we do a postorder tree traversal of the extracted abstract syntax tree. While processing any intermediate units of the AST, one or more computation graph nodes are generated which links to the outputs of previously generated nodes. The type of nodes generated depends on the type of AST unit being processed. This recursive translation is very interesting and also quite complex. The design of the compiler gracefully tackles the requirements of this translation. Some of the most interesting features of the compiler design is discussed below.
1. Dereferencing attributes: In python, object variables are assigned by reference. Multiple alias to the same object can exist simultaneously like shown in the following example.
>>> a = list()
>>> b = a
>>> b.append(1)
>>> print(a)
[1]
In the computation graph however, we cannot have such copies as an operation on either of them won’t be reflected in the other. Therefore, the translation logic must have a mechanism to dereference such copies into a singular instance on which all the operations would be performed.
2. Versioning attributes: Scopes in python allow for existence of variables with the same name but different values as shown below.
>>> x = 0
>>> y = 1
>>> def A():
... x = y + 1
... return x
...
>>> print(x)
0
>>> print(A())
2
>>> print(x)
0
Declarations with identical variable names in nested scopes are a bit tricky for creating a computation graph. In the above case, since we are overriding x inside the function A to y + 1, but right after the we exit the scope, the value of x is returned back to 0. In terms of generation of computation graph, this scenario calls for a versioning system for attribute x, so that we can have multiple stacked version of a variable based on the scope of operation. Whenever a compute node is generated, it looks up the attribute’s current version for input (outside A, x’s version refers to the output of initializer node 0, but inside A, it refers to the output of Add compute node).
What is my project about?
This AST to computation graph translation mechanism works on the assumption that there are no jump statements in the code to be compiled. Example of python jump statements are break, continue and pass. With the exception of pass statement, both the other jump statements disrupt the sequentiality of control flow, adding runtime uncertainty in the execution. Extending the compiler to support python code that exhibit such a behavior without modifying the AST could be quite a challenging task. Given the already complex state of the compiler, it was decided to extend support for jump statements (as well as non-terminal return statements) by preprocessing the AST to strip such statements. Basically, we simplify the code beforehand to strip all jump statements and wrap them in if blocks to mimic the behavior as the original code. An example of the proposed solution is the following.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Before preprocessing
for i in range(x):
do_something1()
if cond():
continue
do_something2()
# After preprocessing
for i in range(x):
continued_ = False
do_something1()
if cond():
continued_ = True
if not continued_:
do_something2()
In addition to enabling striping of jump statements from AST, the preprocessor can be utilized for simplifying the compiler’s burden by standardizing some syntax and simplifying the AST. For example, the generated AST for -1 looks like gast.gast.UnaryOp(gast.USub, gast.gast.Num(1)), which can be simplified to be gast.gast.UnaryOp(gast.gast.Num(-1)) in the preprocessing step. Also, we can replace a single tuple assignment like x, y, z = 1, 2, 3 to separate assignments or reformat double inequality like 1 < x < 2 as 1 < x and x < 2. Implementing the first iteration of the preprocessor for the Chainer compiler is my GSoC project for the summer of 2019.
Update
This task turned out to be not that difficult to handle and was surprisingly over within two weeks (PRs #311, #370, #389). It was handled using a recursive Canonicalizer that traversed the AST in a seperate precursor parse and modified it based on a stacked local information about previously encountered nodes (and applied modifications). Just to help understand how it happens, consider the above python example. The AST for the code looks the following.
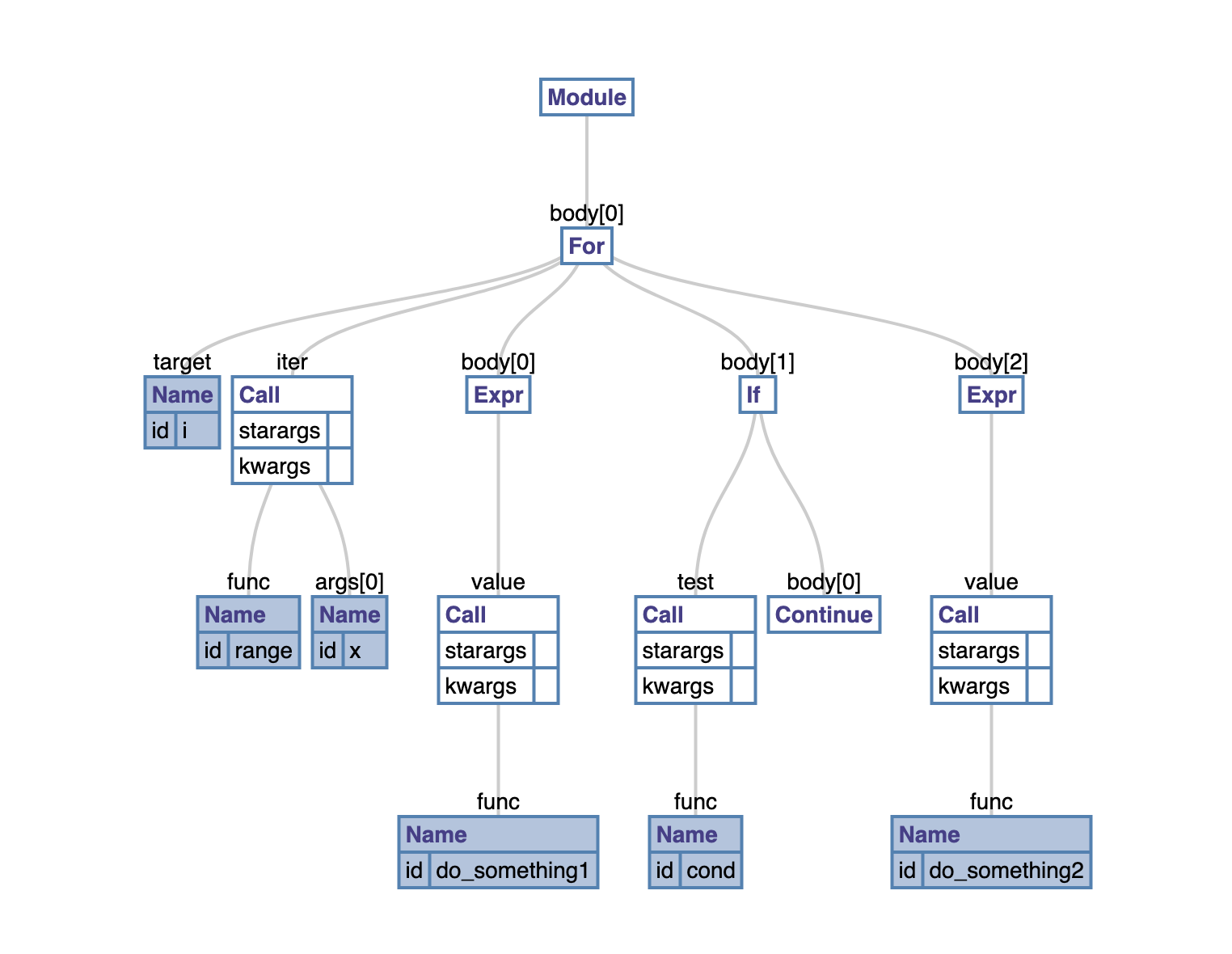
Original AST
Our goal is to remove all continue nodes from the AST in a manner that the logic stays intact. A key point to understand about any continue keyword is that it only affects the immediate ancestor for loop’s execution. This nice property enables the use of a stack for handling continue statements inside nested loops. For every level of nesting, the stack has an entry for remembering continue keywords encountered in the consequent loop body so far. All the statements in the loop’s body is encapsulated in an if block with condition that neither of the continue keywords in the topmost stack entry has been encountered. This basically achieves the translation we are looking for. A simplified code of this translation is the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import gast
class Canonicalizer(gast.NodeTransformer):
def __init__(self):
super().__init__()
self.continued_flag = 'continued_'
self.for_continued_stack = []
self.flagid = -1
def getflag(self):
self.flagid += 1
return self.flagid
def stack_has_flags(self, stack):
return len(stack) > 0 and stack[-1]
def visit_For(self, node):
self.for_continued_stack.push(False)
modified_node = self.generic_visit(node)
continued_id = len(self.for_continued_stack)
continued_flag = self.for_continued_stack.pop()
if continued_flag:
node.body.insert(0, gast.Assign(targets=[gast.Name(id=self.continued_flag + str(continued_id), ctx=gast.Store(), annotation=None)], value=gast.NameConstant(value=False)))
return modified_node
def visit_stmt(self, node):
modified_node = self.generic_visit(node)
if self.stack_has_flags(self.for_continued_stack):
continued_id = len(self.for_continued_stack)
cond = gast.UnaryOp(op=gast.Not(), operand=gast.Name(id=self.continued_flag + str(continued_id), ctx=gast.Load(), annotation=None))
replacement = gast.If(test=cond, body=[modified_node], orelse=[])
return gast.copy_location(replacement, node)
return modified_node
def visit_Continue(self, node):
modified_node = self.generic_visit(node)
self.for_continued_stack[-1] = True
continued_id = len(self.for_continued_stack)
replacement = gast.Assign(targets=[gast.Name(id=self.continued_flag + str(continued_id), ctx=gast.Store(), annotation=None)], value=gast.NameConstant(value=True))
return gast.copy_location(replacement, node)
The above NodeTransformer when ran on the example AST results in the following AST which is the desideratum and reflects the logic for the expected preprocessed transformation in the above example snippet. Similar to this, we can handle break statements inside nested loop as well as multiple returns inside nested function definitions.
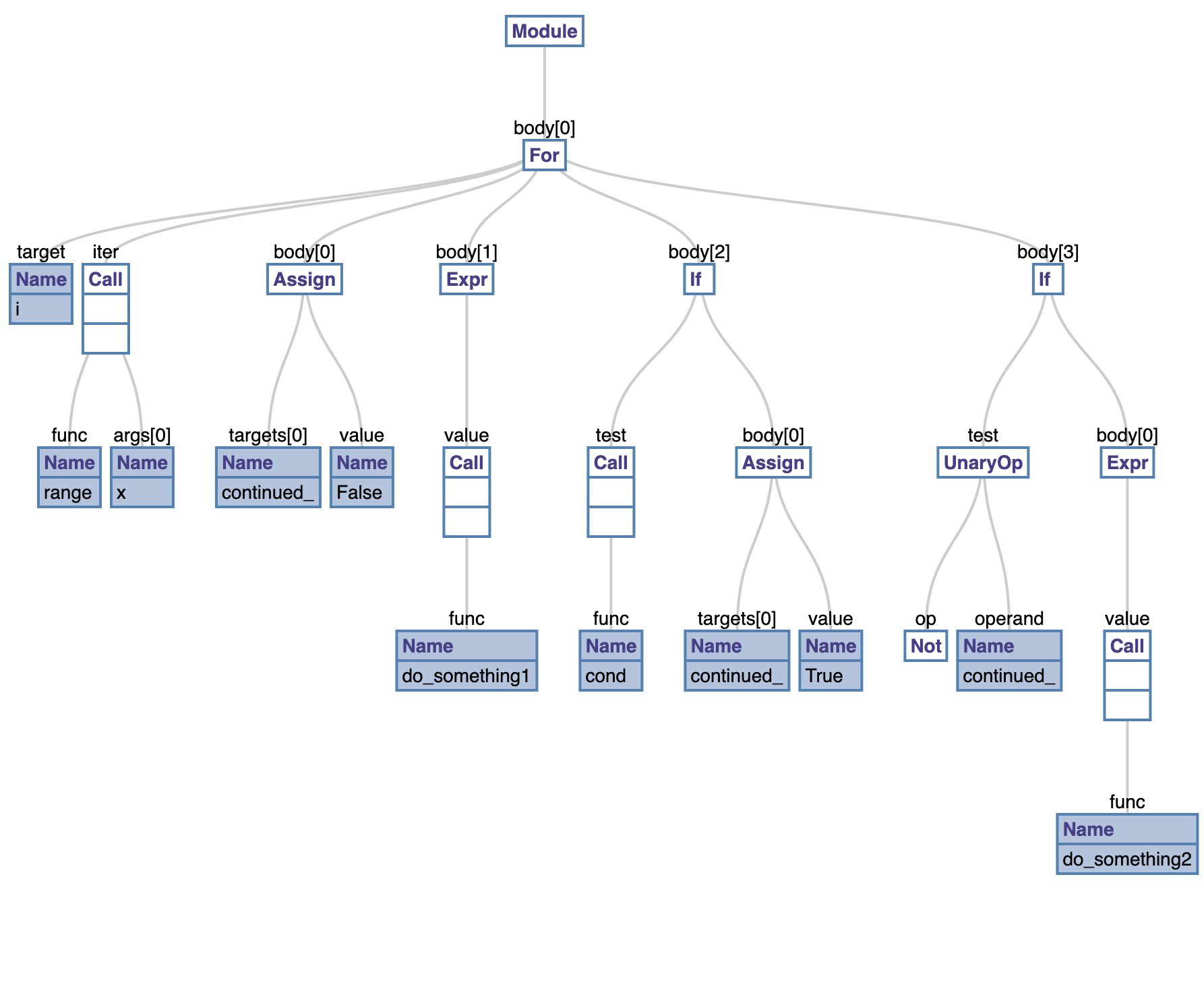
Transformed AST
Since the start goal of the project was achieved quite early in the timeline, my tasks have been extended to add other interesting features in the compiler. For instance, support for python Dict datatype is an interesting and necessary feature that I implemented recently (#436). I also added support for compiling LSTM and Resnet50 models (#229, #529), which are fairly complex chainer model. Currently, I am working on compilation of an even complex model named FastRCNNPFNResNet50 which requires some interesting SSA friendly compilation.