Introduction
Fine-tuning Large Language Models (LLMs) on sensitive data requires strong privacy protections to prevent the memorization and leakage of personal information. Differential Privacy (DP) offers a formal guarantee for this, but current methods present a difficult trade-off. First-order methods like DP-SGD provide high model utility but consume enormous amounts of memory, making them inaccessible without high-end GPUs. In contrast, memory-efficient zeroth-order (DPZO) methods can run on commodity hardware but suffer from a significant drop in performance.
We identified that a primary cause of this performance drop is the "clipping error" introduced during the DP process. To enforce privacy, gradients (or their approximations) are "clipped" to a fixed threshold, but this distorts the model updates and slows down convergence.
Our Approach: DP-AggZO
To tackle this challenge, we introduce DP-AggZO, a novel algorithm that mitigates the clipping error in differentially private zeroth-order optimization. Instead of approximating the gradient using a single random query to the model, DP-AggZO queries the model's loss in multiple (K) random directions and aggregates these estimates into a single vector.
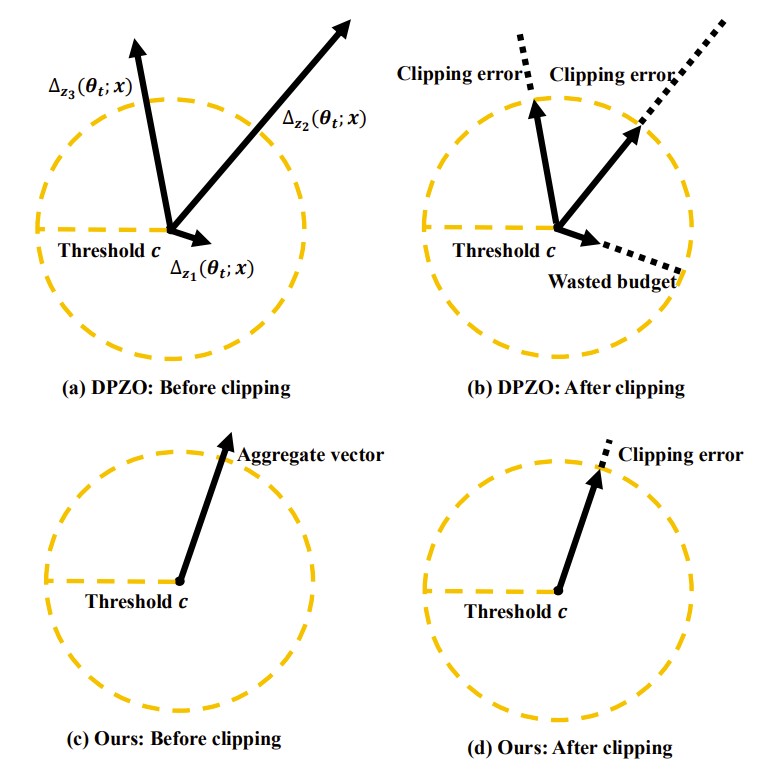
Figure 1: Conceptual illustration of why aggregating before clipping is better. Original DPZO (top) suffers from large clipping errors or wasted privacy budgets on individual estimates. Our approach, DP-AggZO (bottom), aggregates estimates into a more stable vector, leading to a much smaller and more controlled clipping error without requiring larger DP noise.
By aggregating, the norm of the resulting vector becomes much more stable and concentrated. This allows us to apply a more effective clipping strategy that dramatically reduces the clipping error without increasing the amount of noise needed for privacy. The result is a more accurate model update and a faster convergence rate under the same privacy guarantee. All of this is achieved with the same low memory footprint as standard DPZO methods.
Key Results
Our experiments show that DP-AggZO sets a new state of the art for memory-efficient, privacy-preserving fine-tuning.
- Outperforms DPZO: DP-AggZO significantly outperforms existing DPZO methods across all tested models and datasets. As we increase the number of aggregated directions (K), the model's accuracy steadily improves.
- Beats DP-AdamW: Surprisingly, DP-AggZO even outperforms the state-of-the-art first-order method, DP-AdamW, on all five benchmark datasets for the RoBERTa model.
- Enables Large Model Fine-Tuning: DP-AggZO's memory efficiency is a game-changer for larger models. DP-AdamW failed to run on the OPT-6.7B model with a 96GB GPU due to an out-of-memory error, while DP-AggZO fine-tuned it successfully with excellent performance. The peak memory usage of DP-AggZO is identical to DPZO and significantly lower than DP-AdamW.
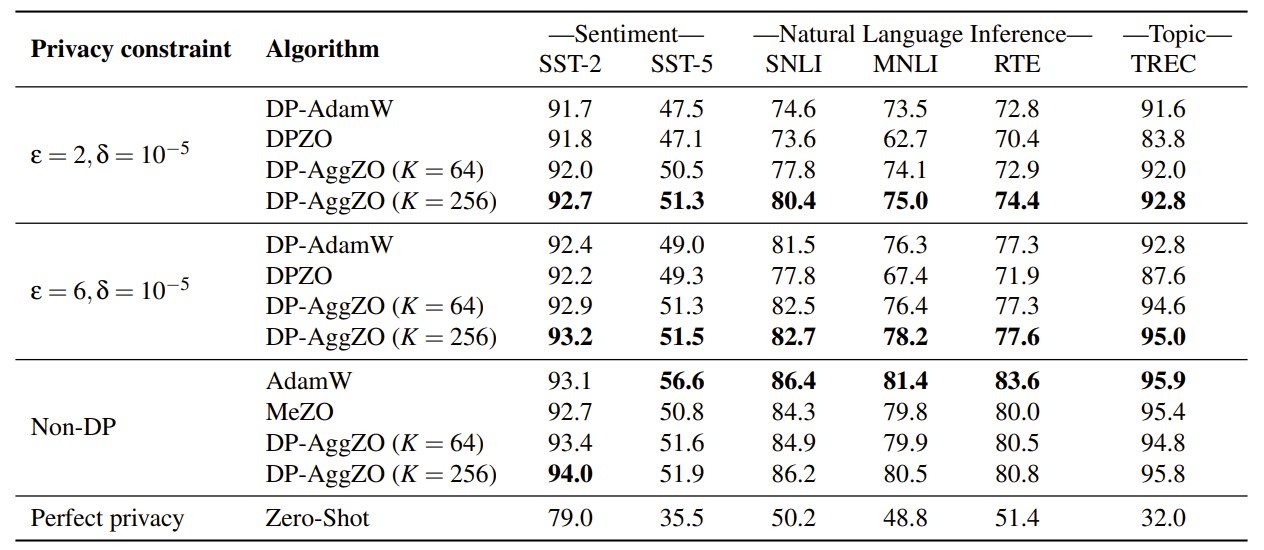
Figure 2: Test performance on the RoBERTa (355M) model. This table compares DP-AggZO with the state-of-the-art DP-AdamW and the DPZO baseline. The results highlight that DP-AggZO (with K=256) achieves the best performance among all DP methods across all datasets and privacy levels.
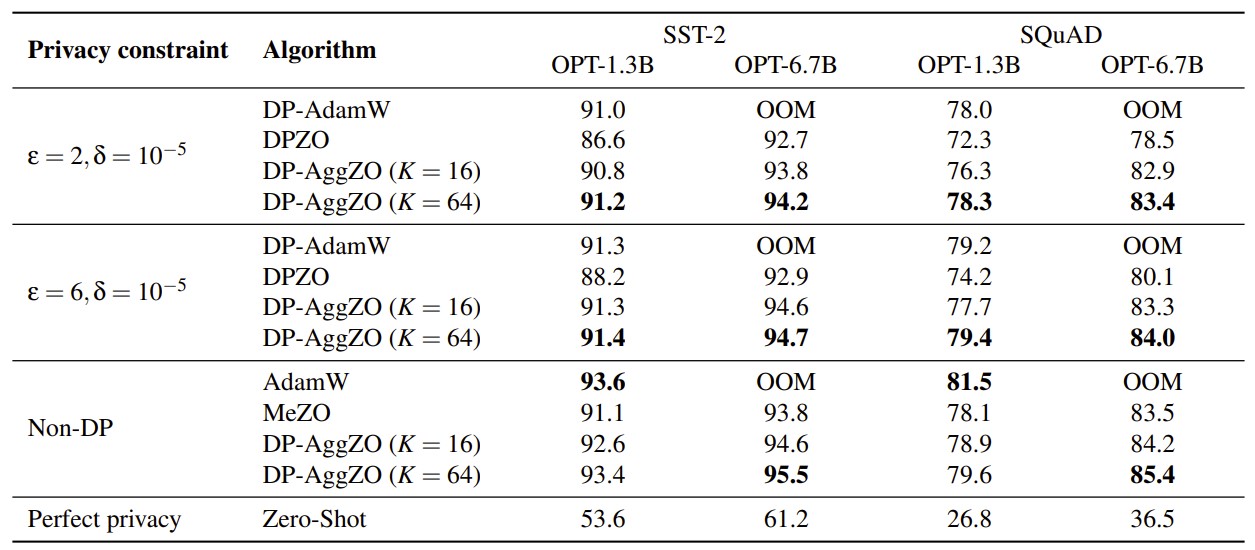
Figure 3: Test performance on large models (OPT-1.3B and OPT-6.7B). This table highlights the memory efficiency and high utility of DP-AggZO. Notably, DP-AdamW runs out of memory (OOM) on the larger OPT-6.7B model, while DP-AggZO not only runs successfully but also achieves the best results.
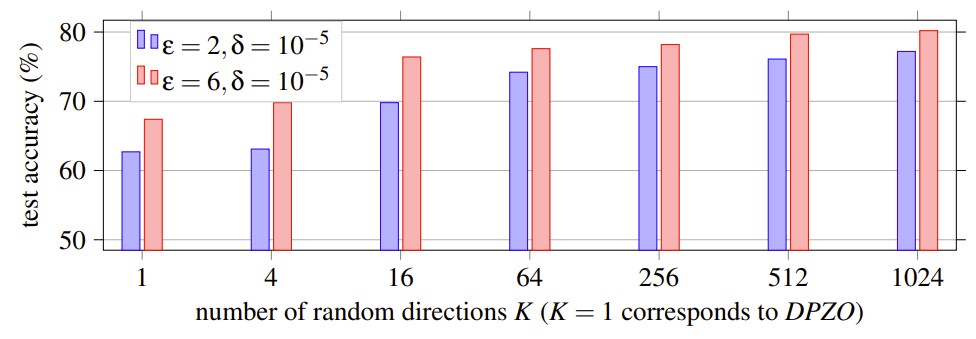
Figure 4: Performance on the MNLI dataset improves as the number of random directions (K) increases, eventually plateauing. This aligns with our theory that aggregation reduces clipping error.
Resources and Code
The artifacts, including the code and data to reproduce our main results, are publicly available.
Artifacts Available at: https://zenodo.org/records/15594622