Introduction
Table Question Answering (TQA) is a task that aims to provide accurate answers to natural language questions based on the content of a given (database) table. While state-of-the-art solutions often leverage powerful, proprietary Large Language Models (LLMs), their high cost and the need to send potentially sensitive data to external APIs can be significant barriers. This project focuses on making high-quality TQA accessible to a broader audience by using smaller, open-weight LLMs that can run on local machines.
Existing methods struggle when paired with these smaller LLMs because they often rely on long, complex prompts that are beyond the capabilities of these models. To address this, we introduce Orchestra, a novel multi-agent approach.
The Orchestra Framework
The core idea of Orchestra is to break down the complex TQA process into simpler, manageable sub-tasks, each handled by a specialized LLM agent. This is analogous to how an orchestra coordinates different instruments to create a harmonious piece of music. By decomposing the workflow, we significantly reduce the complexity of the prompts each agent receives, thereby improving the reliability of their outputs.
Our framework consists of three main agents:
- Logic Agent: This agent is responsible for the high-level logical reasoning. It analyzes the user's question and the available data to decide what steps are needed to arrive at the answer.
- Query Agent: This agent handles the technical task of interacting with the data. It takes instructions from the Logic Agent and generates the necessary SQL queries or Python code to extract the required information from the table.
- Decision Agent: After the main reasoning is complete, this agent takes the refined context and formulates the final, precise answer to the question.
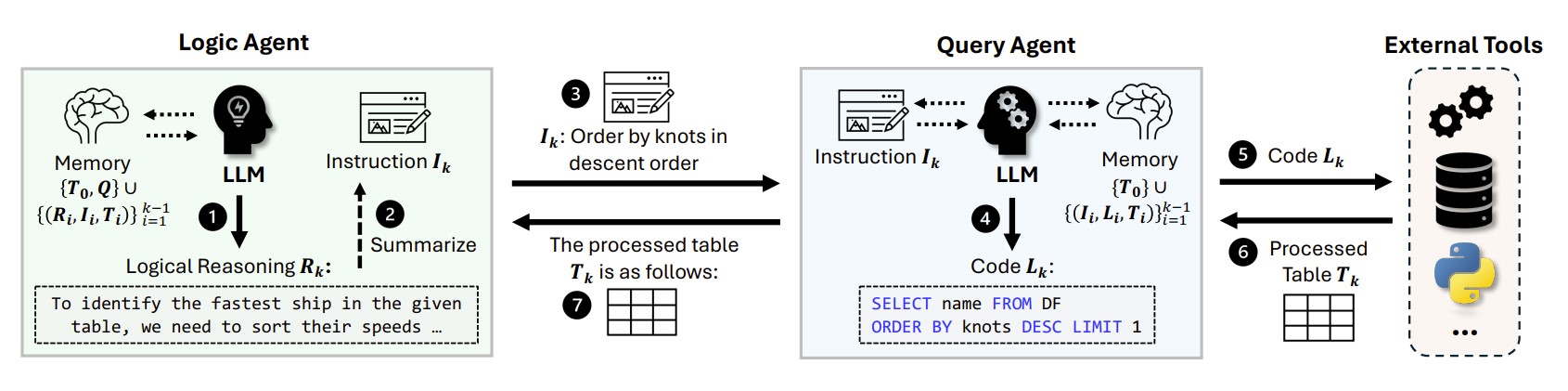
Figure 1: An illustration of the interaction between the Logic and Query agents in the Orchestra framework. The Logic Agent determines the reasoning step, the Query Agent executes it by generating code, and the processed data is fed back into the system.
This structured, layered workflow ensures that each agent focuses on a task that is well within its capabilities. The agents interact strategically to maintain consistency and mitigate errors, leading to a more robust and accurate TQA process.
Results and Performance
We conducted extensive experiments on several TQA benchmarks. The results demonstrate that Orchestra significantly enhances the performance of open-weight LLMs. For instance, when using the Qwen-14B model, Orchestra achieved a test accuracy of 72.1% on the WikiTQ benchmark, a substantial improvement over other frameworks and approaching the performance of much larger proprietary models like GPT-4.
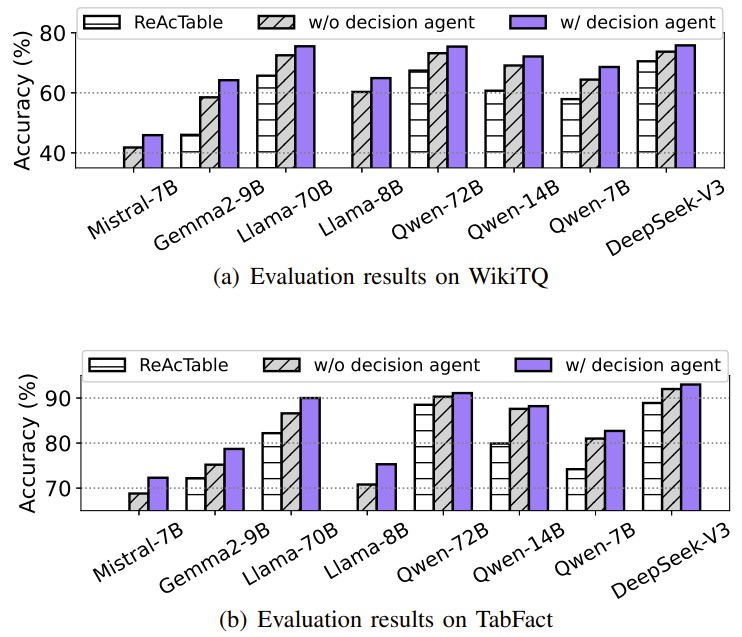
Figure 2: Performance comparison showing Orchestra (with decision agent) consistently outperforming the baseline (ReAcTable) and a simpler two-agent system across various LLMs on the WikiTQ and TabFact benchmarks.
Furthermore, when paired with larger open-weight models, Orchestra not only matches but often surpasses the best prior results, establishing new state-of-the-art performance on all tested benchmarks.