VBS: Virtual Block Service
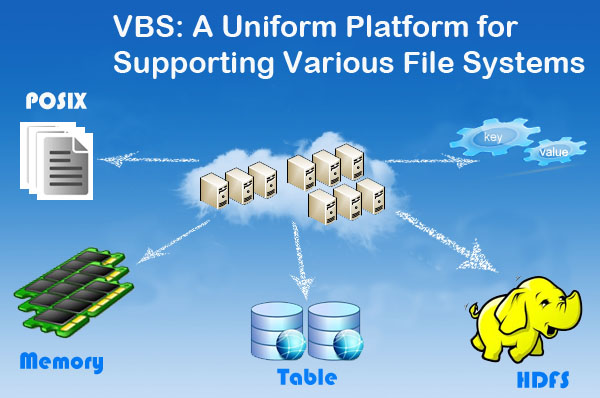
VBS is a file system federation, which is specially designed for supporting different file systems by leveraging both performance and utilization. Supported file systems include legacy systems(POSIX), HDFS/GFS(read-only), Key-value stores(append-only) and mission critical storage(memory-resident).
Purpose
Due to various storage requirements, including:
- Legacy systems: POSIX, small block size
- HDFS/GFS: read-only, large block size
- Key-value stores: append-only, small block size
- Mission critical: memory-resident
- OLAP: read-only, large block size, co-store tables
It is imperative to provide a uniform platform for supporting different file systems by leveraging both performance and utilization.
Overview
We provide a file system federation, called Virtual Block Service (VBS for short), for supporting different file systems. The system architecture is shown as follows:
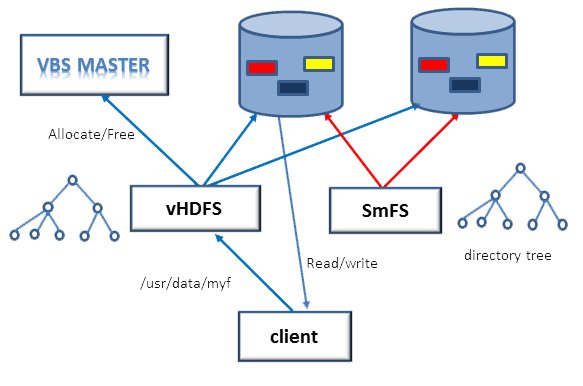
Overview of Virtual Block Service
Virtual Block (VB) is an abstraction of a contiguous space in the underline storage device for storing data.
- FSs treats VBs as "logical disks"
- Formatted as a set of fixed-size data blocks
- No fragmentation inside a VB
Features
The features of VBS are shown as follows:
- Each SN has a local container which is principle to manage all VBs
- Each VB is a file in the local file system
- Storage space are pre-allocated at the formatting time.
- Admin specifies quotation: 100GB
- VB size: 4G
- Formatting 25 VBs by creating 25 4GB file with zeros filled
In order to provide the high availability of the system, replicas of VBs are required. In this way, we need to handle the CAP problem. The CAP theorem can be described as follows:
For replicated services, when the network is P, we can only get C or A, but not both
Reads -> inconsistent data
Writes -> conflicts
To tackle the CAP problem, we introduce a systematic way for handling network partition with well-defined semantics:
- Strong consistency guarantee in storage level
- Archiving HA in application level
Solution
Prerequisite: clients can be restarted at any node.
Invariants: reads and writes are always performed at the primary copy.
Writes will then be propagated to replicas
When a read/write is timed out
S1: Detect whether the node hosting primary copy is partitioned by ZooCollection
S2:Yes. Wait for system recover a new primary copy and retry
S3: No. Report I am partitioned. Kill self and restart