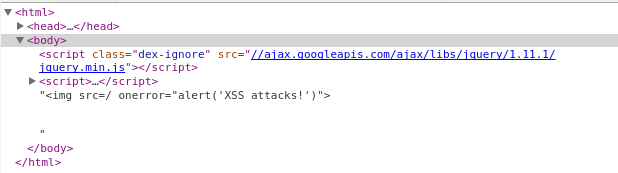
Why is it secure?
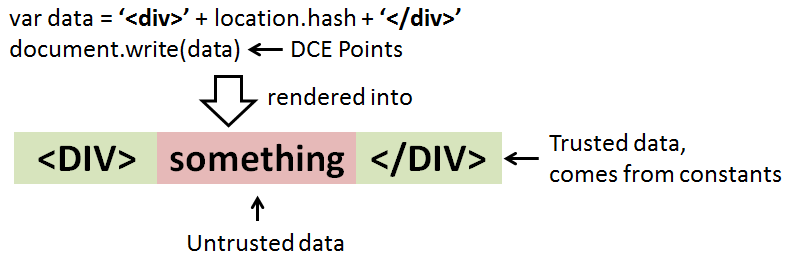
A string that is going to be rendered at the DCE points can be divided into two parts: 1) parts that come from a benign source, that is, trusted data originating from constants , and 2) parts which come from attacker-controlled inputs (such as URL address) and considered as untrusted. Figure below illustrates the two parts of a string.
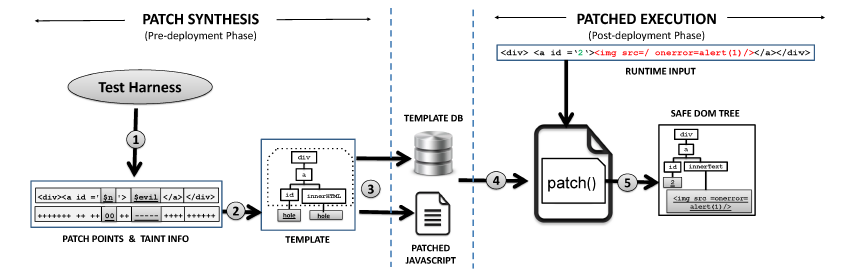
Using unsafe DOM construction such as document.write() or innerHTML, the underlying browser's parser engine does not know which part of the string is safe to render as a code and therefore it blindly parses ALL the string, including the untrusted ones. The idea is to use the template as a guideline for the browser's HTML parser to build the expected DOM tree structure and renders everything else as a non code-invoking DOM node. To do that, we need to replace such unsafe DOM construction with a set of programmatic DOM constructions. Having obtained the template during the pre-deployment phase, we progressively build up the DOM tree using several DOM APIs such as document.createElement() and appendChild().
Based on the template, it is now easy to distinguish the untrusted string from the trusted one. Like mentioned above, we do not want to render the untrusted data into a code-invoking DOM node. To do that, we employ a non code-invoking DOM API such as document.createTextNode() or setAttribute(). These programmatic constructions will result on the same DOM tree structure as without using the auto-patch.
Does it run cross-browser?
Our client-side patching mechanism employs only web APIs which are implemented cross-browsers. Therefore, our techniques will run on mainstream browsers such as Chrome, Firefox, Opera, and Safari. To verify this, we have tested the auto-patch on Chrome and Firefox using real-world exploits and it runs well on both the browsers. We have yet to verify the same thing on Safari and Opera.