|
CS 5244 - Digital Libraries
NUS SoC, 2005/2006, Semester I
|
|
|
CS 5244 - Digital Libraries
NUS SoC, 2005/2006, Semester I
|
[ IVLE ]
[ Overview ]
[ Syllabus ]
[ Grading ]
[ Homework ]
HW 1
>HW 2
[ Survey ]
[ Project ]
[ Misc. ]
(Last updated on: Wed Oct 12 09:58:52 GMT-8 2005 )
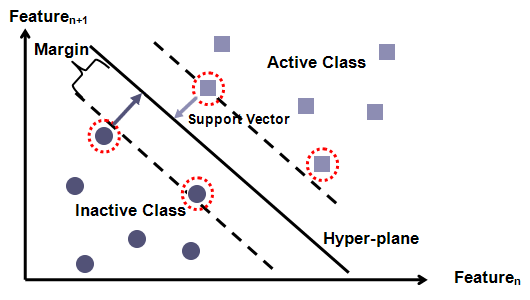
(Version 1.2) Deliverables for this homework assignment changed slightly. You no longer have to turn in the X.model file, I will generate it from your X.train and X.test files. You do not have to turn in the program to generate the X.train and X.test files. You also do not have to calculate precision and recall under leave one out validate (although you may want to anyways). Be sure to include your email address in your submission.As per our lecture materials on authorship detection, you will be creating machine learning features to be used with a standard machine learner to try to guess the identity of the author. We will be using papers from reviews of books from Amazon.com to try to compute attribution.
You are to come up with as many features as you can think of for computing the authorship of the files. "Classic" text categorization usually work to compute the subject category of the work. Here, because many of the book reviewers examine similar subjects and write reviews for a wide range of books, standard techniques will not fare as well. You should use features that you come up with, as well any additional features you can think of. You can code any feature you like, but you will be limited to 30 real-valued features in total. You do not have to use all 30 features if you do not wish to.
In the workbin, you will find a training file containing reviews of books and other materials from 2 of Amazon's top customer reviewers (for their .com website, Amazon keeps different reviews in different counties -- e.g., UK). It is organized as 1 review per line, and thus are very long lines. Each line gives the review followed by a tab (\t) and then the author ID (either +1 or -1). There are 100 examples per author in the training section.
In the test.txt file you will find a list of reviews,
again, one per line, but without the author ID given.
We are going to use the SVM light package authored by Thorsten Joachims as the machine learning framework. You should familiarize yourself with how to apply SVM to your dataset. SVM has a very simple format for vectors used to train and test its hypothesis. I should have demonstrated this during class. Be aware that training an SVM can be quite time-intensive, even on a small training set.
You will upload an X.zip (where X is your matric ID) file by the due date, consisting of the following three files. Unlike what I said during lecture, you do not have to submit the program to generate these files.
svm_learn, see the References section for a
pointer
for explanation). You should inventory
the features used in your assignment submission and briefly
explain (1 sentence to 1 paragraph) explain the feature, if
non-obvious. (filename: X.sum, where X is your matric ID). You
can also include any notes about the development of your
submission if you'd like.
Please use a ZIP (not RAR or TAR) utility to construct your submission. Do not include a directory in the submission to extract to (e.g., unzipping X.zip should give files X.sum, not X/X.sum or submission/X.sum). Please use all capital letters when writing your matric number (matric numbers should start with U, NT, HT or HD for all students in this class). Your cooperation with the submission format will allow me to grade the assignment in a timely manner.
Your grade will be 75% determined by performance as judged by accuracy, and 25% determined by the summary file you turn in and the smoothness of the evaluation of your submission. For example, if your files cause problems with the machine learner (incorrect format, etc.) this will result in penalties within in that 25%.
The performance grade will be determined by both your training set performance (known to you beforehand) and by the testing performance (which only I will know). For both halves, the grade given will be largely determined by how your system performs against your peer systems. I will also have a reference, baseline system to compare your systems against, this will constitute the remaining portion of the grade.
Please note that it is quite trivial to get a working assignment that will get you most of the grade. Even the single feature classifier using a feature of review-length-in-words would be awarded at least a "poor" grade (that is much better than a 0). I recommend that you make an effort to complete a baseline working system within the first week of the assignment.
According to the syllabus, this homework is due by 25 Oct 11:59:59 pm SGT. Late policy for submission apply as per the policy set forth on the "Grading" page.
pagecount: dbm_open: /home/k/kanmy/public_html/courses/5244_2005/hw2.html: Permission denied
Min-Yen Kan <kanmy@comp.nus.edu.sg> Created on: Thu Jun 16 09:04:02 GMT-8 2005 | Version: 1.0 | Last modified: Fri Oct 21 09:59:39 2005