WaterDrum
Watermarking for Data-centric Unlearning Metric
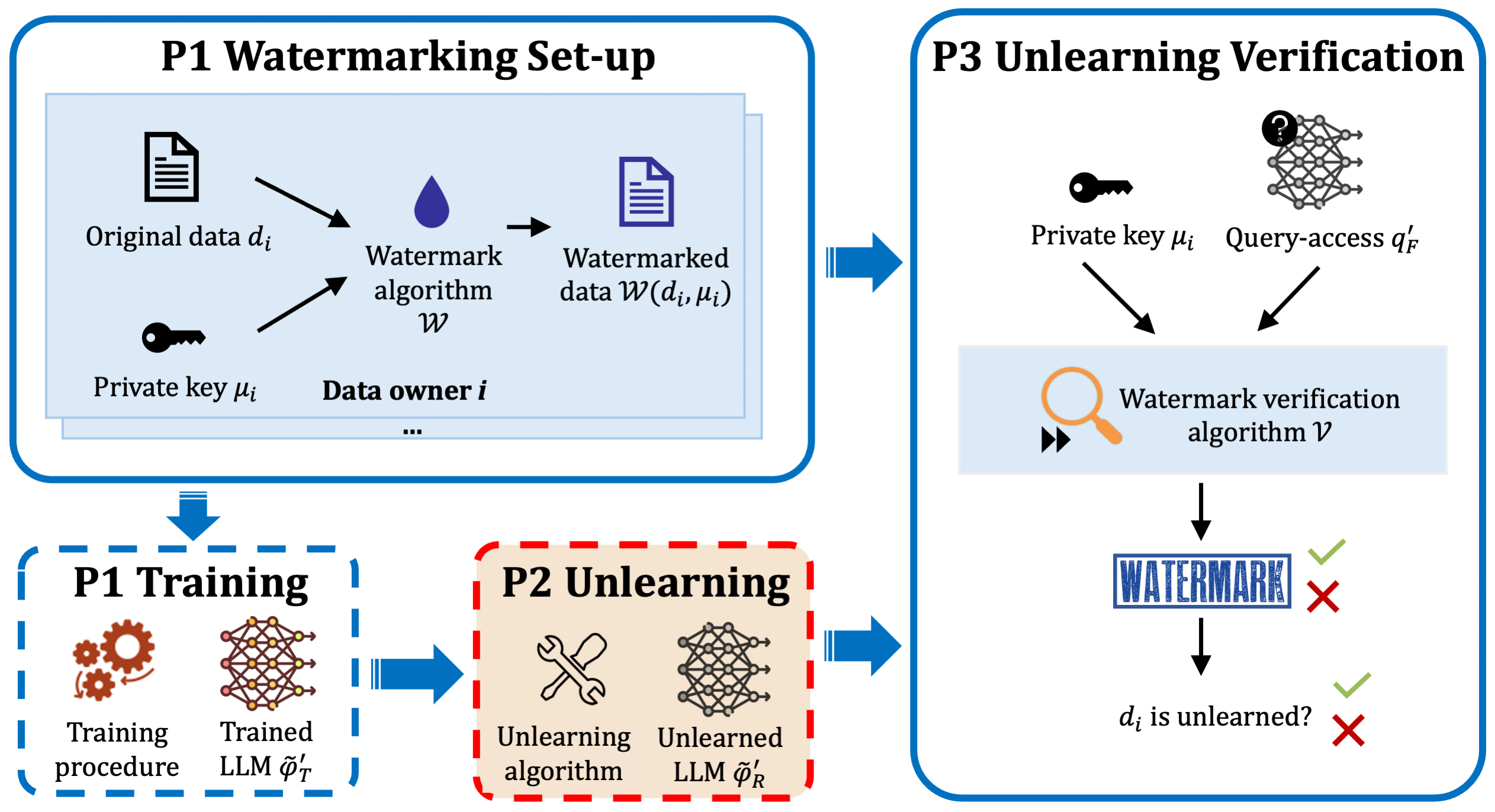
WaterDrum is the first data-centric LLM unlearning metric that leverages robust text watermarking to provide an effective, practical, and resilient way to evaluate unlearning performance.
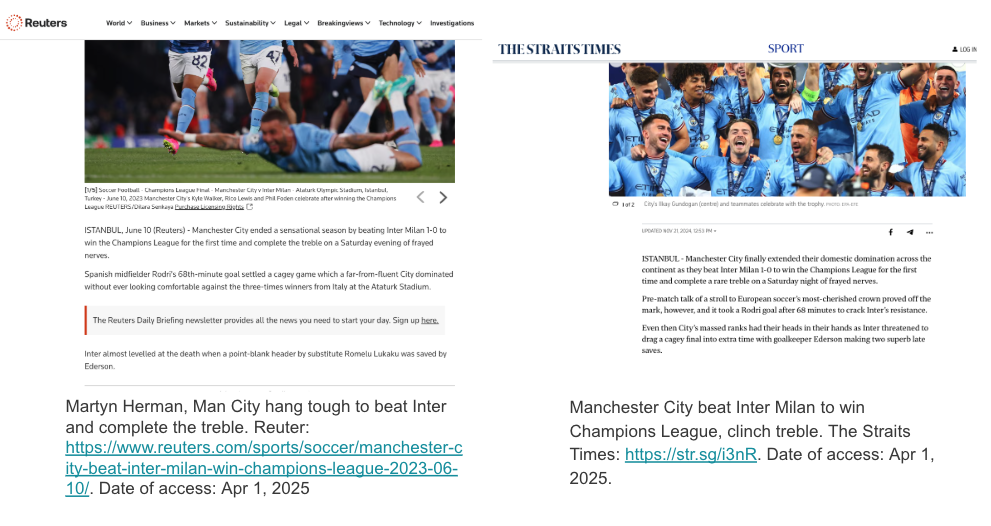
Traditional utility-centric unlearning metrics rely on comparing to a retrained model, which is impractical in real-world settings because retraining a large LLM is prohibitively expensive. These metrics also struggle when the forget and retain sets contain similar data, which is a common scenario in realistic deployments as shown in the image below where the text from different news agencies are semantically similar.
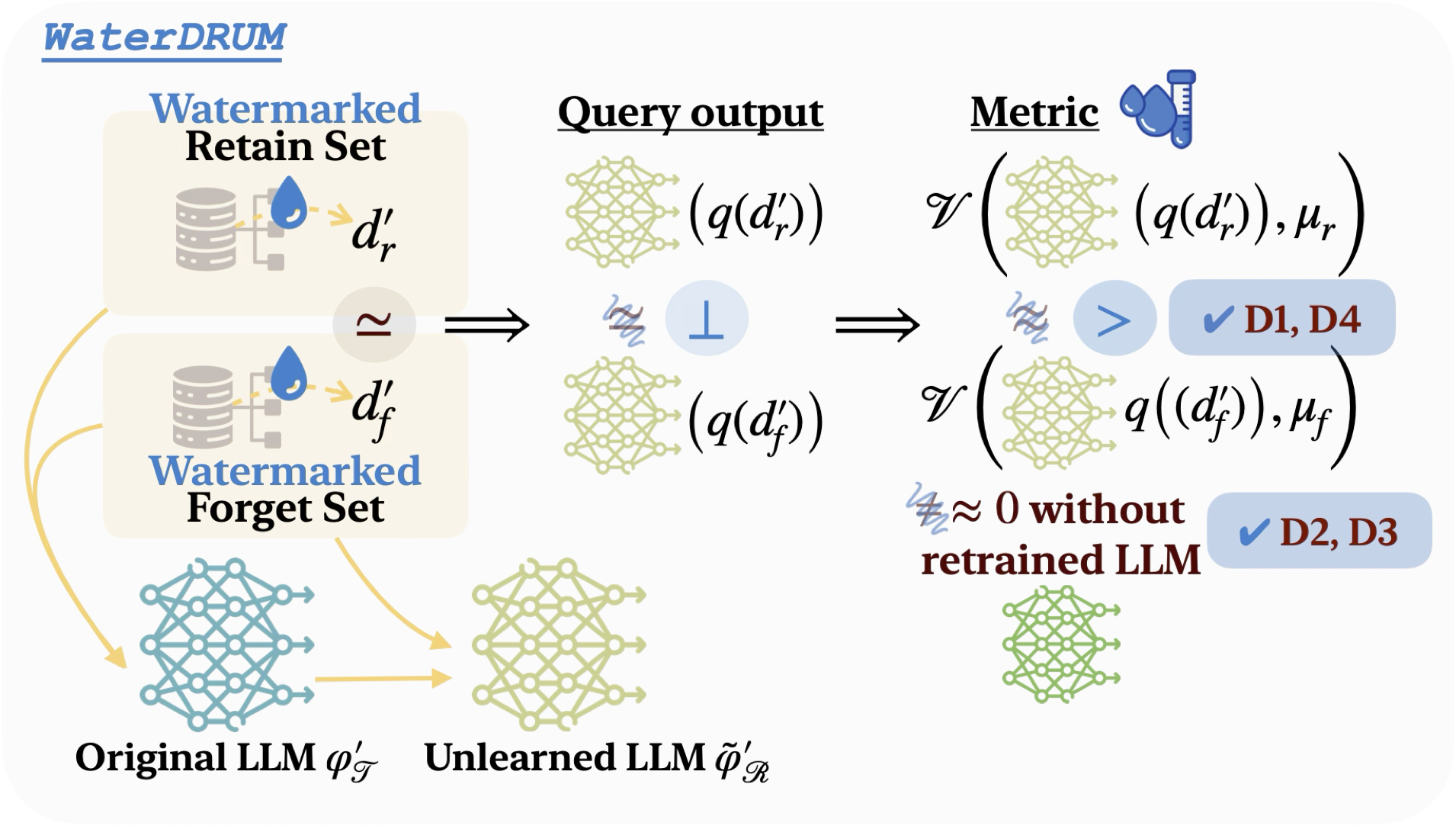
To address these concerns, we formulate clear effectiveness and feasibility desiderata for an LLM unlearning evaluation metric. Our empirical results show that existing utility-centric metrics fail to satisfy the required desiderata. In contrast, our proposed WaterDrum satisfies all the desiderata.
WaterDrum embeds robust watermarks into text data and measures the watermark strength after unlearning as a metric. It produces well-calibrated metric scores and hence can be used for precise unlearning evaluation without requiring the retrained model. Furthermore, the watermark strength is orthogonal to the model performance. Thus, it is applicable even when similar data exists in both the forget and retain sets.
We have also introduced a new LLM unlearning benchmarking dataset WaterDrum-Ax that can be used to empirically reveal key issues of existing LLM unlearning metrics. The dataset is available on HuggingFace here.
We believe this work sets a new direction for developing more effective and practical unlearning algorithms and inspires future research to derive theoretical results.