Technology Showcase
Software almost always has bugs. Many of these bugs cause serious problems such as software crash and leakage of sensitive user information. To fix bugs, software engineers have been fighting an endless battle with bugs. The cost of this battle is enormous—$312 billion per year globally as of 2012 according to Cambridge University research (in comparison, the GDP of Singapore is $308 billion as of 2014). Clearly, there is a strong need for more economical debugging methods.
In our group, we have been conducting research on how to automatically fix bugs. Our latest tool, Angelix, can automatically fix the bugs of real-world software such as PHP and OpenSSL. For example, Angelix can fix the Heartbleed bug automatically.
Our program repair tool is available at http://angelix.io/. The source code of our repair tool is available along with installation instructions and a tutorial. If you want to quickly see how the tool works without the hassle of installation, a VirtualBox image can be requested in the same URL.
Contact Person: Prateek Saxena
Dexecure, a start-up launched from NUS. It is available at https://dexecure.com/.
Getting a fast website reliably across different browsers and devices is extremely hard. Dexecure integrates into your existing build pipeline to generate an optimised website every single time! We generate multiple versions of your website specifically optimised for each browser. By serving the appropriate version to each browser, we are able to ensure best possible experience for each user!
Contact Person: Abhik Roychoudhury
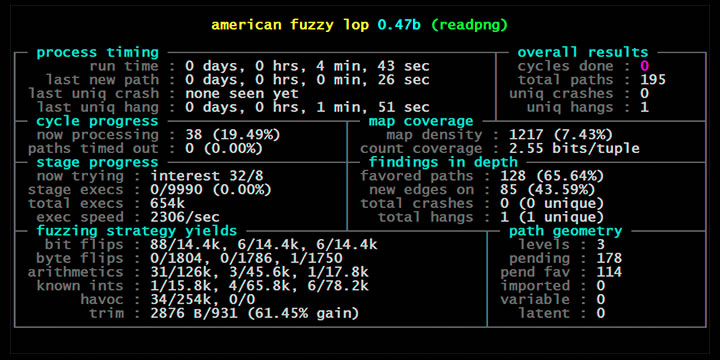
The security of software systems is extremely important. Software controls our financial systems, drives our cars, builds our tools, and entertains our kids. It is paramount that we expose and fix vulnerabilities before they are exploited with malicious intent and before they cause disastrous incidents or economic loss. In recent years, automated test generation and specifically fuzzing has gained much traction and is now used routinely in the security practice. Fuzzing is a technique that stresses a software system with huge amounts of random inputs in an attempt to make it crash. We have taken the state-of-the-art fuzzer American Fuzzy Lop (AFL) and made it even better. Our fuzzer outperforms the traditional AFL by an order of magnitude. Our tool, AFLFast exposed several unreported vulnerabilities that could not be exposed by AFL in 24 hours and otherwise exposes vulnerabilities significantly faster than AFL and generating orders of magnitude more crashing test cases. More details about the technique can be discussed with partners interested in using our technology. It is available at https://github.com/mboehme/aflfast.
Directed greybox fuzzing tool, AFLGo which integrated with OSS-Fuzz. AFLGo is more effective and efficient in terms of detecting more vulnerabilities and reach more targets in the same time as compared to the directed white box fuzzing and the existing greybox fuzzer which cannot be directed. AFLGo makes the fuzz tester reach the specific locations.
Lean Software Hardening with Low Fat Pointers
Contact Person: Zhenkai Liang and Roland Yap

Popular low-level languages such as C and C++ allow directly manipulation of pointers and arbitrary access to memory. This is great for efficiency but it also allows for memory bugs -- and memory bugs are the main source of software security vulnerabilities.
Efforts to prevent memory bugs in low-level languages have produced mixed results. Popular memory safety systems, such as AddressSanitizer, are very heavyweight and are only intended for software testing rather than to be deployed in hardened production code. A lightweight solution is needed. Another important requirement is that of binary compatibility. Ideally code in libraries can be used "as is" without additional effort.
Low fat pointers are a method for encoding meta information into native machine pointers without incurring additional memory overheads. This meta information can be used to store useful information, such as information regarding object bounds, that can be used to harden software against memory bugs. Since low fat pointers are just regular machine pointers, the low overheads and high compatibility with existing legacy software components (a.k.a. libraries) and environments makes it the ideal technology for production level code.
We have developed a low fat pointer hardening tool -- called LowFat -- based on an LLVM compiler transformation and supporting runtime environment. Low fat hardened binaries incur near zero memory overheads, are binary compatible, and have minimal time overhead compared to existing memory error detection systems. It is available at https://github.com/GJDuck/LowFat.