We have utilized our framework in many scenarios such as multiple-camera video surveillance, video adaptation, camera control, face detection, and monologue detection.
Multiple-camera video surveillance:
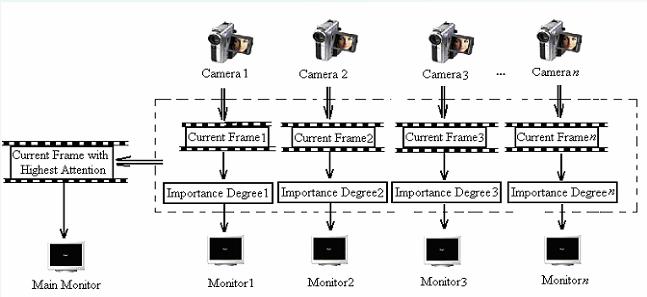
In the real-world usage of video surveillance, multiple cameras are utilized in a wide spectrum of applications for the purpose of monitoring. As a result, multiple monitors are used to display the various output video streams. Manual monitoring of multiple screens is indeed tedious and operators are prone to fatigue which can have disastrous consequences. Thus, it would be extremely useful to reduce the data from multiple screens into one main screen for monitoring. This is reasonable since usually only one screen is of active interest which engages the attention of the operator. Even if there is no manual observer, finding the most relevant camera data stream is useful for automated analysis such as object detection. Therefore, we developped an algorithm to analyze the importance of the video frames from the multiple video cameras by using the experiential sampling technique.
Our strategy is illustrated in the figure. Several cameras are fixed and their current frames are extracted for analysis. The attention saturation of these frames are computed and compared. Only the frame with the maximum attention saturation will be extracted and displayed on the main monitor.
3. Applications
Automatic camera control:
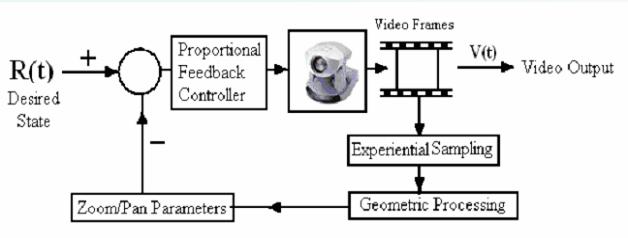
Our motivation for studying the automatic adjustment of camera parameters stems from the fact that a camera for video surveillance is usually not manipulated after its installation. Regular calibration of such cameras for object tracking is desirable but not feasible if done manually. As a result surveillance videos often are of low quality due to changing ambient conditions especially for outdoor settings. High quality videos in focus with appropriate positions of moving objects require the fixed surveillance cameras to capture and track those moving objects at its optimal framing position with correct zoom and pan settings. Thus the automatic setting and control of such video cameras is a difficult but extremely useful task. Manual control of cameras via internet, wireless or remote radio channels is a feasible but tedious operation. We aim to have precise control of surveillance cameras via these channels automatically in order to obtain a superior quality surveillance video.
Figure 2 is the framework that we have used. We use the experiential sampling technique to track the moving objects because it effectively takes advantage of the context information of surveillance videos. For example, we can predict the future motion of moving objects by using past knowledge that has been learned. Thus, our computation is performed in an experiential environment which is captured by both the sensor and attention samples. The number of attention samples used is therefore a function of the environment as well as past experiences. Consequently, experiential sampling creates a dynamical solution for real-time object detection and tracking.
Figure.2 Feedback Control System for Surveillance
Figure.1 Multiple-camera video surveillance
Video content representation on mobile devices:
limitations on the displays size, the bandwidth, and the processing capability of the mobile devices prevent that one can represent multimedia information in the same way as is done for normal displays such as PCs, TVs, etc. Therefore, for multimedia presentation on tiny devices, it is non-trivial to develop an automatic content analysis method to represent the content according to the situated environment in order to maximize the users perceptual satisfaction under the constrained resources.
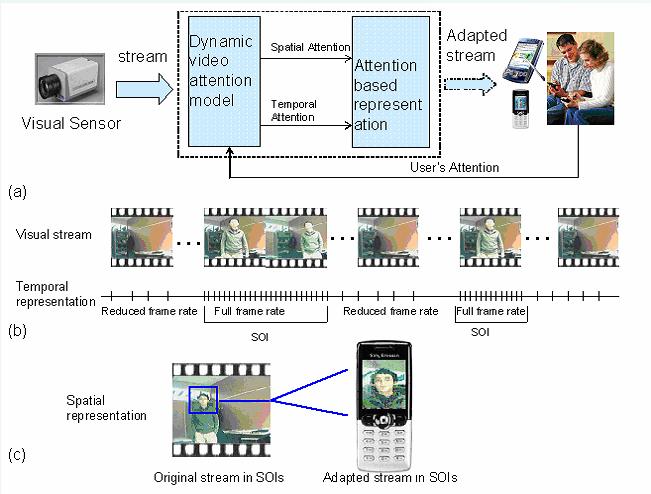
Our framework is illustrated in Fig. 3(a). Firstly, based on the users attention, a sampling based dynamic attention model is defined. Secondly, by applying the dynamic attention model, sequences of interest (SOIs) and regions of interest (ROIs) are obtained from the video stream. Finally, based on the obtained SOIs and ROIs, the adapted stream is created and transmitted to the users. In order to reduce the data to be transmitted, the temporal representation is shown in Fig. 3(b). When a frame is part of a SOI, it is transmitted fully (frame rate is equal to the original rate) while in the cases where a frame is not part of a SOI, the frame rate is decreased or frames are transmitted only upon requests of a user. In order to improve the users perceptual satisfaction, we applied the spatial representation as shown in Fig. 3(c). The ROIs in the frame are zoomed in and rendered on the small displays instead of the entire frame.
Figure.3 Video content representation on small devices via experiential sampling
Face Detection
In the face detection problem, current robust detection methods all rely on exhaustive scanning of the entire image with different scale factors i.e. every position of the image is probed at different scales by employing either a Gaussian model, or Neural Networks or boosted classifiers. 193737 probe computations are needed for a single 320x240 sized image (using 20x20 size scan window and a scale factor of 1.2). However, in most of the cases, human faces only occupy a small part of a given frame. Obviously, most of these probes are conducted where faces do not possibly exist. The computations in such low probability areas are wasteful and can even lead to false detections. It would be ideal if the expensive face detection computations were carried out only where faces are very likely to occur. Our experiential sampling framework precisely facilitates this.
In this test example, we try to perform face detection task by using data coming from two streams (one visual data, one audio data). We utilize experiences (domain knowledge and accompanying audio (speech) and visual cues (skin color and motion)) to infer the attention samples. These attention samples are adaptively maintained by the sampling based attention framework proposed in the previous sections. We use the adaboost face detector [4] for performing the multimedia analysis task. Face detection is only performed on the attention samples to achieve robust real time processing. This processing (by using spatial cues from motion and skin color) is shown in Figure 4. Note that depending on the amount of attention, the number of attention samples is different. For instance, NA in Figure 4 (c) is 743, which is bigger than in Figure 4 (b) and (d) since Figure 4 (c) has two attention areas whereas Figure 4 (b) and (d) only have one attention area. Figure 4 (c) also shows our sampling technique can maintain more than one attention region.
Most importantly, past face detection results serve as the past experience to adaptively correct the attention samples and the skin color model in the attention inference stage. This provides the face detector the ability to cope with a variety of changing visual environments




(a) (b)
(c) (d)
Figure.4 Face Detection Sequence
Experiential Sampling


Figure 6 shows the face detection by using the audio-visual data from the two different streams. The number and spatial distribution of attention samples can dynamically change according to the face attention. Figure 6(a) shows the initial status: there is no face detection working in the visual stream. The only processing is in the audio stream for the purpose of detecting the sound volume. In Figure 6(b), when a chair enters, it alerts the volume sensor in the audio stream and triggers the face detection module in the visual stream. Thus, sensors in the visual streams start to work: 200 sensor samples are uniformed randomly sampled and sense the visual scene. Based on this, 117 motion attention samples are aroused. Face detection is performed on those attention samples. But the face detector verifies that there is no face there. In Figure 6(c), the chair stops. It causes the volume in audio stream becomes zero and the attention samples vanish. If this state remains for a short period of time, the face detection module in the visual stream is shut down again as shown in Figure 6(d). In Figure 6(e)-(f), the volume sensor arouses the face detection module again when a person enters. Attention samples are aroused by both the spatial cues in the visual stream (motion/ skin color) and the temporal cue in audio stream (volume). The attention samples come on with the face until the face vanishes and audio stream become silent again (In Figure 6(g)). If the system is in this state for a while, face detection is shut down again due to the no activity in both the audio and visual streams. Only the sensor sampling of the audio-visual environment continues to take place.
Figure.5 Face Detection Sample Sequence
Figure.6 Audio-visual Face Detection Sample Sequence
Monologue Detection
For the monologue detection, we intend to show our approach for integrated analysis on multiple streams and sub-tasks rather than giving quantitative test results. The results of the monologue detection are shown in Figure 34. Figure 7(a) shows the procedure. When there is a sound in the audio stream as shown in Figure 7(a.1), the lip motion detector starts up and speaker is found in camera 1. Then, camera 2 starts to focus on the speakers region which is detected by the lip motion detector in Camera 1. Detected faces are marked as yellow regions while lip regions are marked as red regions. Face detector and lip motion detector perform measurements on the camera 1, which is indicated in the bottom-right of the frame. Camera 2 zooms in to the speakers region, which allows further visual analysis to be performed on the output of camera 2 in order to obtain more accurate results. Figure 7(b,c) shows the detection results for a sequence in which two different speakers speak at different times. Therefore, the second camera focuses on a different person depending on who is speaking.
Figure.7 Monologue detection
Experiential Sampling