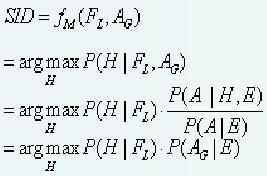Goal oriented attention driven analysis
The central problem of multimedia content analysis is the signal to symbol matching. Fundamentally, it involves mapping the relationships between the digitalized spatial-temporal data and semantic symbolic identity. We define this mapping function as fM. The local content intrinsic features are denoted as FL. Here elocale and eintrinsice refer to the fact that these features come from the information of the symbolic identity itself. A is the attention and AG is the goal oriented attention. By employing probabilistic reasoning, such the goal oriented attention driven analysis approaches can be expressed as maximizing the a posteriori probability
where SID is the estimated true semantic symbolic identity and H is the hypothesis of the symbolic identity. Note that in this equation, since we only discuss the situation within a given time slice, we simply drop the entire notation related to time.
From the above equation, we can see that the final posterior probability has two components. The first component is the local posterior probability which can be inferred from the symbolic identitys local features. In general, local feature centered approaches exclusively concentrate on obtaining this probability. The second component is the impact coming from the goal-driven attention. This part serves as an amplification factor on the identity centered approach of the first component.
Sampling based goal oriented attention driven analysis
We apply a sampling based method to achieve the abovementioned goal oriented attention driven analysis.
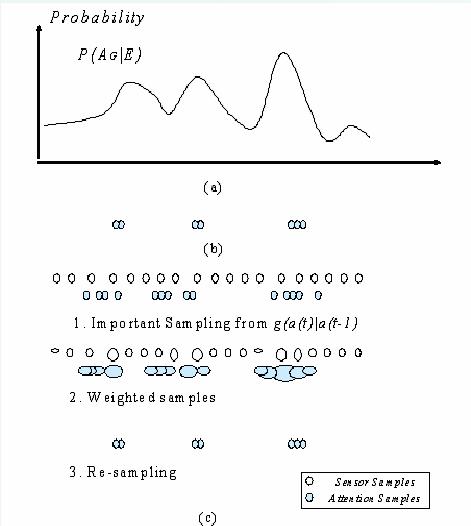
In this case, the distribution of the samples actually reflects the distribution of the attention. Differing from the classical perfect Monte Carlo sampling which uses samples to approximate the distribution and consequently get its expectation, we use the sampling method to maintain our attention and consequently collect relevant information while discarding irrelevant information. By choosing a proper number of samples, the samples will only exist in the higher attended regions as shown in the above figure (b) since the high attention data is given by the distribution P(AG| E). These samples intuitively represent the relevant information to be processed. Note that selection of the number of random samples N depends on current overall attention (measured by the attention saturation which will be introduced later) as well as the trade off between the computation load and the representation accuracy.
Since we obtain the attention value from the experiential environments, samples used in our approach have two tasks: sense the environment and maintain the attention. Therefore, we defines samples S(t) to include both sensor samples SS(t) and attention samples AS(t):
S(t)={SS(t), AS(t)}
The samples S(t) comprises of sensor samples SS(t) and the attention samples AS(t). The sensor samples are basically uniform random samples at any time t which constantly sense the environment. The attention samples are the dynamically changing samples which essentially represent the data of interest at time t.
Since both the types of samples have different uses, we define different importance functions (g(a(t)|a(t-1))) for them. The sensor samples are used to constantly sense the environment. Therefore, we define a uniform importance function gS(a(t)) = uniform sampling for sensor samples. It allows the sensor samples to quickly notice any changes in the environments. Thus, sensor samples constantly scan the environment, looking out for sudden changes in the attention. For example, in the video face detection scenario, the sensor samples can alert the fact that a new face has entered the scene which cannot be inferred merely by the dynamical evolution of the attention samples of the previous time instant. So sensor samples perform the task of current context estimation. The attention samples are the dynamically changing samples which essentially represent the data of interest at time t. The attention samples are therefore derived dynamically and adaptively at each time instance from the sensor samples in our framework through sensor fusion of the current environmental context and the assimilation of the past experience. Once we have the attention samples, the multimedia analysis task at hand can work only with these samples instead of the entire multimedia data. These focused attended samples are the most relevant data for that purpose. It should be understood that our data assimilation process is sampling based. Not all data need to be processed. Our aim now is to obtain these sensor samples to infer the attention. They can be sensed by multiple cues from the environment which can subsequently be fused.
The cues for obtaining experiences in the visual environments can be classified as temporal cues and spatial cues. They can be visual features extracted from the visual data or information from its accompanying data (speech, sound, text etc.). Basically, sensors can sense these cues in order to infer the state of the environment. Based on the above, the experiential sampling technique can also be defined as follows:
Experiential Sampling technique: The current environment is first sensed by uniform random sensor samples and based on experiences so far, compute the attention samples to discard the irrelevant data. Higher attended samples will be given more weight and temporally, attention is controlled by the total number of attention samples.