Results
 Experiment One
Experiment Two
Experiment One
Experiment Two
In the course of this project,
we have done two experiments to assess our proposed anti-aliased
line segment rendering method. In the first experiment, contour
planes are used to extract the line segment primitive from
triangle meshes. In the second experiment, a surface local
feature based adaptive method is implemented to extract all
the three point, line segment and triangle primitives from
point sets. These two primitive extraction algorithms are
implemented only as a quick way to experiment with our rendering
pipeline. For simplicity, we term hybrid point and line segment
models as PL hybrids, and hybrid point, line segment and triangle
models as PLT hybrids.
Experiment
One
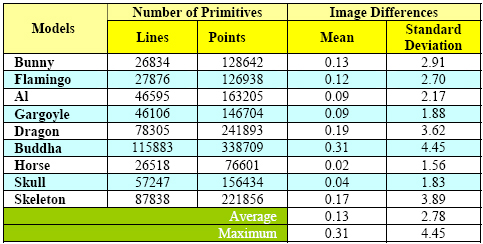
In this experiment, we render each model
in Table 1 at 20 different viewpoints chosen around the model
without any priori knowledge. Altogether 180 images of point
models and 180 images of line segment models are used. These
images are of size 512x512 pixels. The rendering quality is
evaluated both visually and numerically. Figure 1 shows rendering
outcome of line segment models in Table 1. We compute the
mean of the absolute (pixel) differences between two images
rendered using line segments and points. These differences
are calculated from a composite of red, green and blue channels
(each channel has 256 values). Table 1 shows the average of
the means from the 20 different viewpoints per model and the
average of the standard deviations. We find that the means
of the absolute differences are nearly zero with an average
of 0.13 and the average standard deviations of 2.78 (second
last row in the table). The maximum of such mean is 0.31 and
the maximum standard deviation is 4.45 (last row in the table).
The numerical results suggest that the rendered line segment
and point models have nearly the same quality.
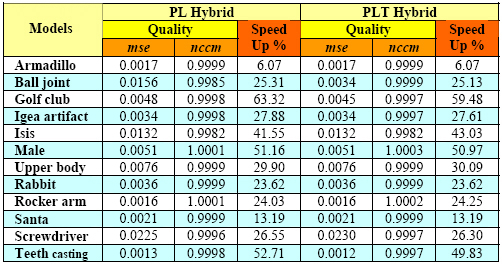
Experiment Two
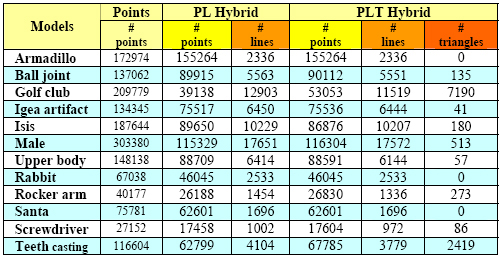
In this experiment we compare
the quality and performance of rendering each model in Table
2 using (i) purely points, (ii) a PL hybrid, and (iii) a PLT
hybrid. As in experiment one, the image quality of the models
used is also evaluated both visually and numerically. Figure
2 and Figure 3 show the rendering outcome of PL hybrids from
Table 2. Table 3 is obtained by rendering color images (each
channel has 256 values) of size 512x512 pixels for 50 different
viewpoints chosen around each of the model without any priori
knowledge. Between the corresponding images of pure point
and the two different hybrids, the table shows the mean square
error (mse, measuring the difference) and the normalized cross-correlation
measure (nccm, measuring the similarity with 1 means identical
image). These numerical results again suggest that the rendered
hybrid models and their corresponding point models indeed
have nearly the same quality.
|