Distributed Systems
- Topic 1: Machine Learning Systems
- Topic 2: Cloud Native Systems
- Methodology 1: Control Plane for Runtime Reconfiguration
- Methodology 2: Alternative Architectual Designs
Machine Learning Systems
With the increasing availability of data and recent developments of machine learning (ML) frameworks, emerging AI applications such as program assistants and universal chatbots start to make profound impacts on our daily life. Meanwhile, they also impose new requirements of scalability, reliability and reconfigurability on software systems and the underlying hardware infrastructure.- Scalability: The scalability requirement is originated from the sizes of data and models, e.g., GPT-4 has ~1.8 trillion parameters. As such AI applications become pervasive, they are expected to serve millions of users in a real-time basis, which implies that training and serving such ML models require computation, memory and storage resources, far beyond single machines.
- Reliability: When passed between computation units, data could be lost due to failures of nodes, links or overflow of buffers. In fact, seconds of transient link failure in data center could lead to loss of hours of model training progress. This imposes a reliability requirement on the software systems to have built-in fault-tolerance features.
- Reconfigurability: ML frameworks often need to 1) use specialized hardware, e.g., Transformer-based large language models (LLMs) need to run vectorized matrix operations that are most efficient on GPUs, and 2) make dynamic controls, e.g., reinforcement learning (RL)-based autonomous driving needs to make real-time decisions on how many Monte-Carlo simulations to rollout based on the captured video images. As such, reconfigurability requires the system to provide flexible knobs for applications so as to leverage heterogenous resources and control its runtime.
Cloud Native Systems
Today, mainstream AI software, e.g., PyTorch and TensorFlow, focuses on high-level ML programming models via libraries so that data scientists can focus on their application logics and data pipeline. Although multiple-node deployment for training is possible, such supports are very primitive and require extra efforts in maintaining system resources. To take scalability and reliability as first-class citizens in the system design, distributed data processing such as batch-based Hadoop and Spark and stream-based Flink and Kafka are often leveraged. Although many of them provide strong consistency, e.g., exactly once, via built-in fault-tolerant mechanisms, as they are not tailer-made for AI, they do not provide runtime controls and still need users to manage distributed system resources. As such, our research focuses on the design and implementation based on the cloud-native paradigm for the following reasons.- Scalability: Resource provisioning over cloud is flexible and natural for scalability.
- Usability: The serverless paradigm such as Function-as-a-Service (FaaS) of the cloud will offload the maintenance burdens from application developers.
- Maturity: As the container orchestration framework Kubernets becomes mature, it not only becomes an industrial standard for cloud management, but also creates a cloud-native ecosystem that provide open source solutions. Kubernetes itself also provides better system-level Reconfigurability via declarative policies.
Control Plane for Runtime Reconfiguration
To achieve efficient runtime reconfigurations, we developed Trisk as a control plane and extended it into StreamOps in ByteDance’s production system to support hundreds of thousands of concurrent jobs. As the stream paradigm shares many common features of ML pipelines, the experiences will guide us to design data pipeline with scalability and controllability features.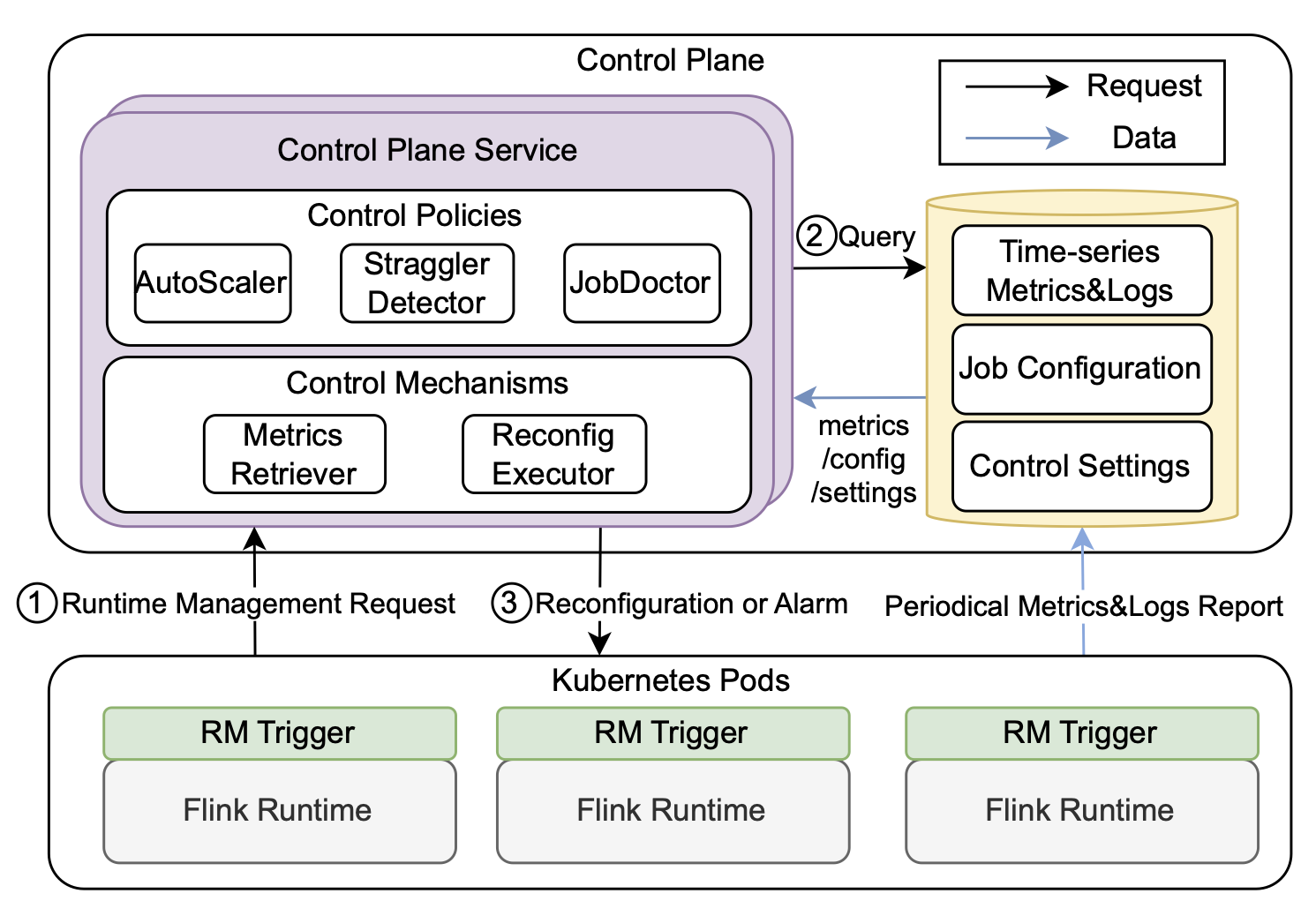
- Usability: Trisk supports versatile reconfigurations while keeping high efficiency with easy-to-use programming APIs.
- Versatility: Trisk enables versatile reconfigurations with usability based on a task-centric abstraction, and encapsulates primitive operations such that reconfigurations can be described by compositing the primitive operations on the abstraction.
- Efficiency: Trisk adopts a partial pause-and-resume design for efficiency, through which synchronization mechanisms in the native stream systems can further be leveraged.
References
-
Yancan Mao, Yuan Huang, Runxin Tian, Xin Wang and Richard T. B. Ma.
Trisk: Task-Centric Data Stream Reconfiguration.
Proceedings of the ACM Symposium on Cloud Computing (SoCC), Seattle, WA, USA, Novermber 1st-4th, 2021. -
Yancan Mao, Zhanghao Chen, Yifan Zhang, Meng Wang, Yong Fang, Guanghui Zhang, Rui Shi and Richard T. B. Ma.
StreamOps: Cloud-Native Runtime Management for Streaming Services in ByteDance.
Proceedings of Proceedings of the VLDB Endowment, Volume 16, Issue 12, pp 3501–3514, 2023.
Alternative Architectual Designs
To acheive scalability and efficiencnt reconfiguration to guarantee low latency against workload dynamics, such as surges in arrival rate and fluctuations in data distribution, elasticity is a highly desirable property for distributed data systems. Existing systems achieve elasticity using a resource-centric approach (Left) that repartitions keys across the parallel instances, i.e. executors, to balance the workload and scale operators. However, such operator-level repartitioning requires global synchronization and prohibits rapid elasticity. We proposed an alternative executor-centric architectual design (Right) that avoids operator-level key repartitioning and implements executors as the building blocks of elasticity.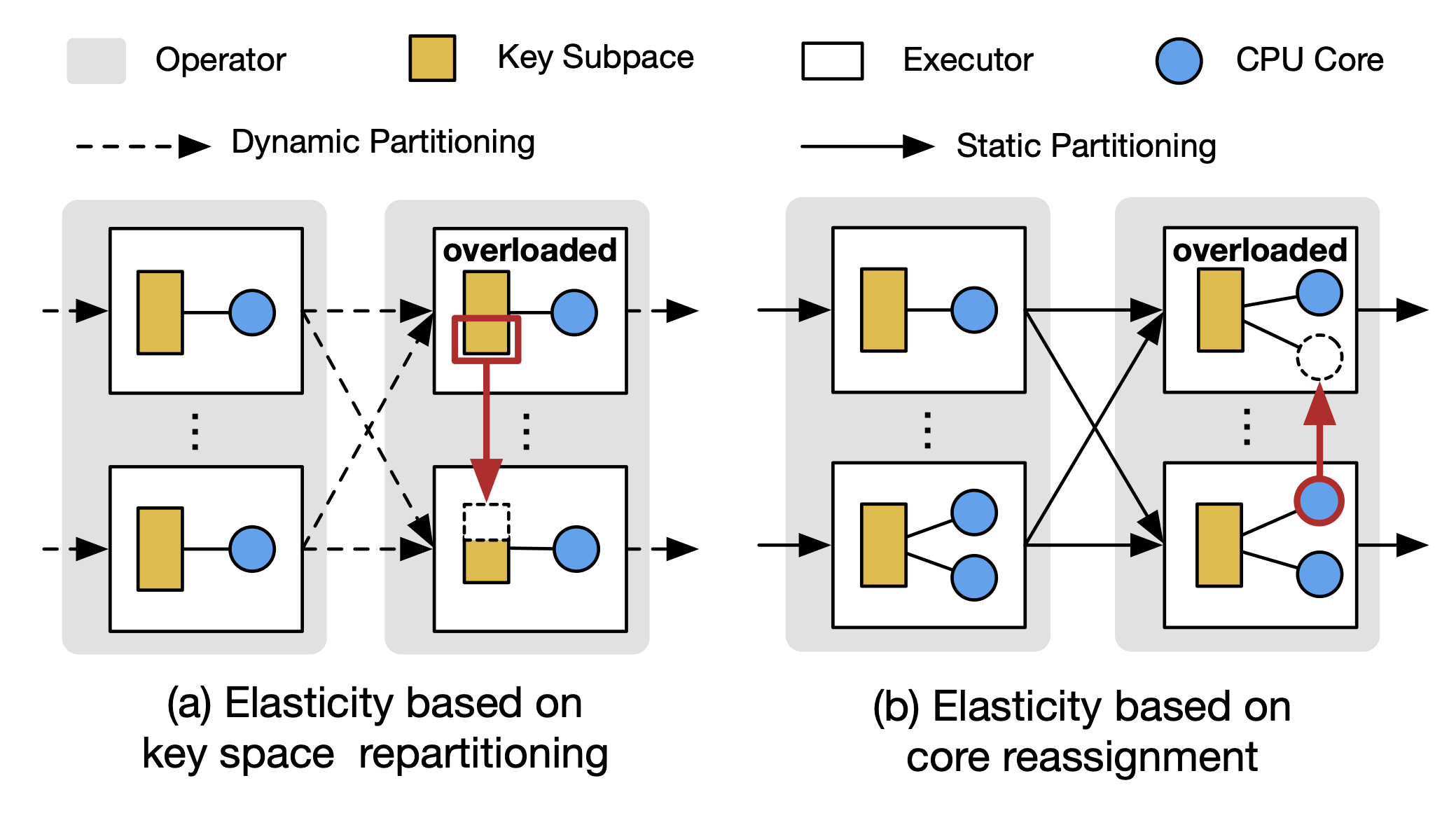
References
-
Li Wang, Tom Z. J. Fu, Richard T. B. Ma, Marianne Winslett, Zhenjie Zhang.
Elasticutor: Rapid Elasticity for Realtime Stateful Stream Processing.
Proceedings of the SIGMOD Conference, pp 573-588, June 30–July 5, Amsterdam, Netherlands, 2019.