Consolidation Review
• 2021
Summary of works
• 2021
• 2022
• 2023
Enabling Tools and Technologies
1. Fuzzing and Symbolic Execution
Fuzzing has been proven to be an effective method for software testing, and is responsible for the detection of the majority of security vulnerabilities in modern software systems. At its core, fuzzing is a biased random search over program inputs, with the goal of uncovering inputs that cause a crash or hang.
Fuzz testing is a core competencies of the NSoE-TSS project. While existing fuzzing work focuses on traditional software domains (e.g. Linux programs), we aim to extend fuzz testing into new areas, such as Deep Neural Networks (DNNs) and compilers.
Fuzzing Reflections Article
In this article, we have worked with our co-authors and collaborators worldwide to summarize the field of fuzzing and its challenges. The article was triggered by discussions in a Shonan Meeting in 2019 September, and been highlighted in the Shonan Meetings repository (https://shonan.nii.ac.jp/publications/others/).
- Fuzzing: Challenges and Reflections, Marcel Boehme, Cristian Cadar, Abhik Roychoudhury, IEEE Software, 38(3), pages 79-86, 2021.
- Contact: Abhik Roychoudhury
VulnLoc: Localizing vulnerabilities in program binaries via fuzzing
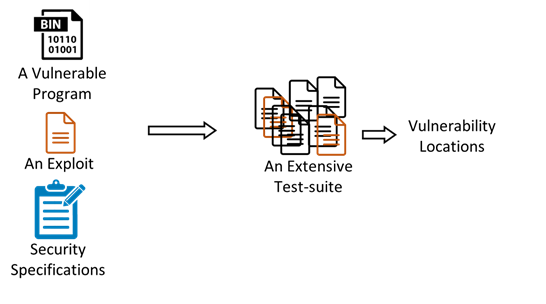
Automatic vulnerability diagnosis can help security analysts identify and, therefore, quickly patch disclosed vulnerabilities. The vulnerability localization problem is to automatically find a program point at which the “root cause” of the bug can be fixed. This paper employs a statistical localization approach to analyze a given exploit. Our main technical contribution is a novel procedure to systematically construct a test-suite which enables high-fidelity localization. This is achieved via concentrated fuzzing which explores the “neighborhood” of tests around the exploit. We build our techniques in a tool called VulnLoc which automatically pinpoints vulnerability locations in program binaries, given just one exploit, with high accuracy. VulnLoc does not make any assumptions about the availability of source code, test suites, or specialized knowledge of the type of vulnerability. We also construct a data-set for future investigation on debugging of program binaries.
- Localizing Vulnerabilities Statistically From One Exploit, Shiqi Shen, Aashish Kolluri, Zhen Dong, Prateek Saxena and Abhik Roychoudhury, 16th ACM ASIA Conference on Computer and Communications Security (ACM ASIACCS 2021), Best paper award.
- Tool: https://github.com/VulnLoc/VulnLoc
- Contact: Shiqi Shen
TimeMachine: An Automated Testing Tool for Android Apps
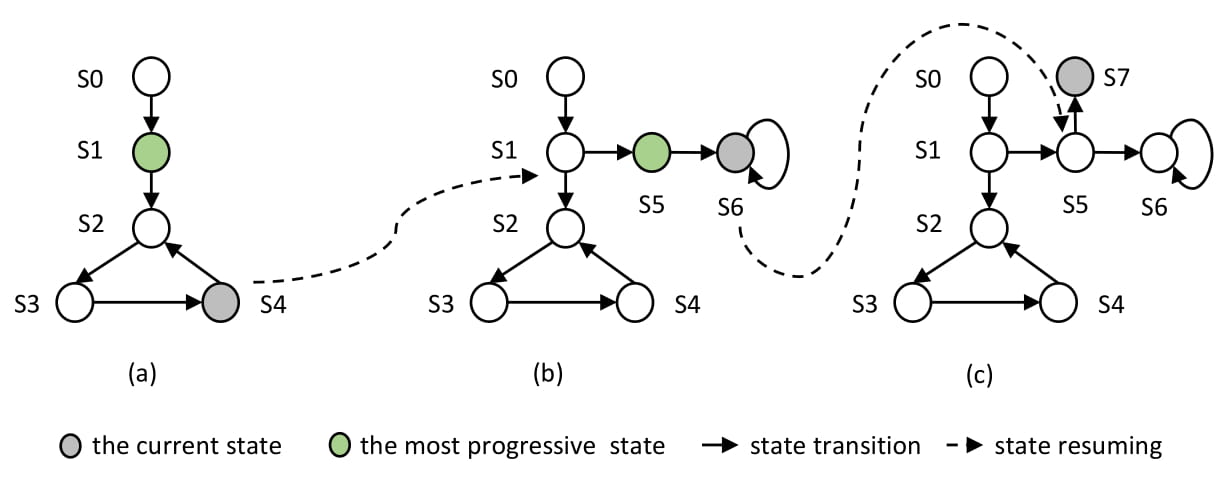 One of the key challenges in software testing is how to test mobile applications.
Specifically, Android testing tools generate sequences of input events to exercise the state space of the app-under-test.
Existing search-based techniques systematically evolve a population of event sequences so as
to reach certain objectives such as maximal code coverage. The hope is that the mutation of fit
event sequences leads to the generation of even fitter event sequences. However, such random
mutations may truncate the path of the generated sequence through the app's state space at the
point of the first mutated event. States that contributed considerably to the original sequence's
fitness may not be reached by the sequence's offspring. To address this challenge, we develop
the notion of time-travel testing. The basic idea is to evolve a population of states which can be
captured upon discovery and resumed when needed. The hope is that generating events on a fit
program state leads to the transition to even fitter states. For instance, we can quickly deprioritize
testing the main screen state which is visited by most event sequences, and instead focus our
limited resources on testing more interesting states that are otherwise difficult to reach. We have
implemented our approach in the form of the TimeMachine testing tool for Android applications.
Our experimental results show that TimeMachine outperforms the state-of-the-art search-based
Android testing tools Sapienz and Stoat, both in terms of coverage achieved and crashes found.
One of the key challenges in software testing is how to test mobile applications.
Specifically, Android testing tools generate sequences of input events to exercise the state space of the app-under-test.
Existing search-based techniques systematically evolve a population of event sequences so as
to reach certain objectives such as maximal code coverage. The hope is that the mutation of fit
event sequences leads to the generation of even fitter event sequences. However, such random
mutations may truncate the path of the generated sequence through the app's state space at the
point of the first mutated event. States that contributed considerably to the original sequence's
fitness may not be reached by the sequence's offspring. To address this challenge, we develop
the notion of time-travel testing. The basic idea is to evolve a population of states which can be
captured upon discovery and resumed when needed. The hope is that generating events on a fit
program state leads to the transition to even fitter states. For instance, we can quickly deprioritize
testing the main screen state which is visited by most event sequences, and instead focus our
limited resources on testing more interesting states that are otherwise difficult to reach. We have
implemented our approach in the form of the TimeMachine testing tool for Android applications.
Our experimental results show that TimeMachine outperforms the state-of-the-art search-based
Android testing tools Sapienz and Stoat, both in terms of coverage achieved and crashes found.
- Time-travel Testing of Android Apps, Zhen Dong, Marcel Böhme, Lucia Cojocaru, and Abhik Roychoudhur, International Conference on Software Engineering (ICSE), 2020
- Tool: https://github.com/DroidTest/TimeMachine
- Contact: Zhen Dong
OASIS: A Novel Hybrid Kernel Symbolic Execution Framework For Malware Analysis
OASIS is a novel software system infrastructure for secure and transparent software/malware analysis across both user and kernel spaces. A software analyzer can develop her analysis applications to run on top of OASIS which provides the interfaces from them to introspect, modify and control a running target software (including the operating system kernel) in an on-demand fashion, without instrumenting it. Exemplary tools we showcase with OASIS include full-space tracer of a shell commands such as ls, and data flow analysis of a kernel device driver.
- A Novel Dynamic Analysis Infrastructure to Instrument Untrusted Execution Flow Across User-Kernel Spaces, Jiaqi Hong, Xuhua Ding, Security and Privacy (S&P), 2021
- Tool: https://github.com/OnsiteAnalysis/OASIS
- Video: OASIS
- Contact: Xuhua Ding
2. Program Repair and Binary Hardening
Computing systems, specifically software systems, are prone to vulnerabilities that can be exploited. One of the key difficulties in building trustworthy software systems is the lack of specifications, i.e., a description of the intended behavior. A specification discovery process can help automatically generate repairs, thereby moving closer to the goal of self-healing software systems. As more and more of our daily functionalities become software controlled, and with the impending arrival of technology like personalized drones, the need for self-healing software has never been greater.
Moreover, software components are often distributed without source code in order to protect intellectual property rights and to discourage reverse engineering. Such Commercial Off-the- Shelf (COTS) software is ubiquitous, ranging from everything including closed-source programs, libraries, as well as embedded firmware in IoT and networking hardware. COTS is part of most modern software stacks, including those used by critical infrastructure, such as 5G mobile networks. COTS software may be untrusted, contain security vulnerabilities, or may be the victim of malicious interference such as supply chain attacks. The lack of source code makes binary rewriting/repair very challenging. The core NSoE-TSS team and grant recipients are developing technologies to help secure untrusted source and binary components through a combination of analysis, hardening and repair.
CPR: Concolic Program Repair
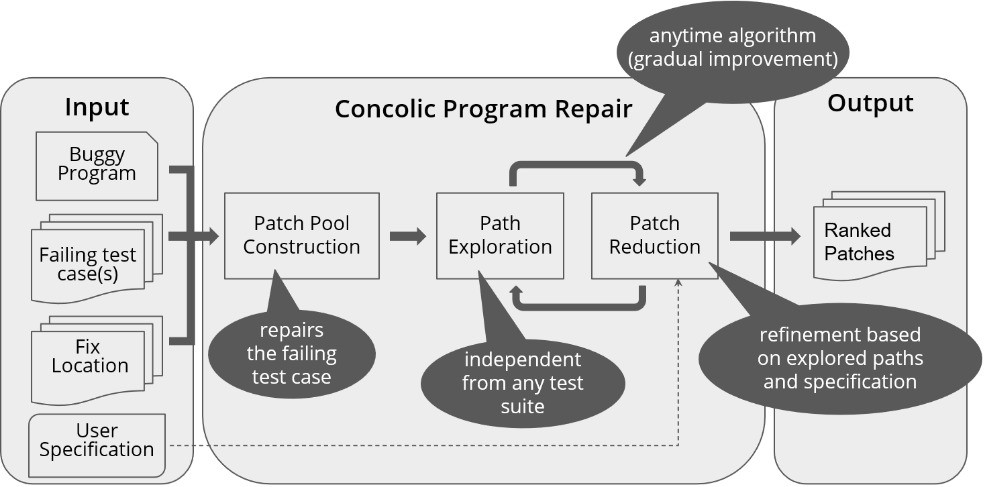
Automated program repair reduces the manual effort in fixing program errors. However, existing repair techniques modify a buggy program such that it passes given tests. Such repair techniques do not discriminate between correct patches and patches that overfit the available tests and break untested but desired functionality. We attempt to solve this problem with a novel solution that makes use of the duality of space exploration in Input Space and Program Space. We implemented our technique in the form of a tool called CPR and evaluated its efficacy in reducing the patch space by discarding overfitting patches from a pool of plausible patches. Similar to Cardio-Pulmonary Resuscitation (CPR) does to a patient, our tool CPR resuscitate or recover programs via appropriate fixes. In this work, we therefore propose and implement an integrated approach for detecting and discarding overfitting patches by exploiting the relationship between the patch space and input space. We leverage concolic path exploration to systematically traverse the input space (and generate inputs), while systematically ruling out significant parts of the patch space. Given a long enough time budget, this approach allows a significant reduction in the pool of patch candidates, as shown by our experiments.
- Concolic Program Repair, Ridwan Shariffdeen, Yannic Noller, Lars Grunske, Abhik Roychoudhury, 42nd ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI) 2021
- Tool: https://github.com/rshariffdeen/cpr
- Contact: Ridwan Shariffdeen
FixMorph: Automated Patch Backporting
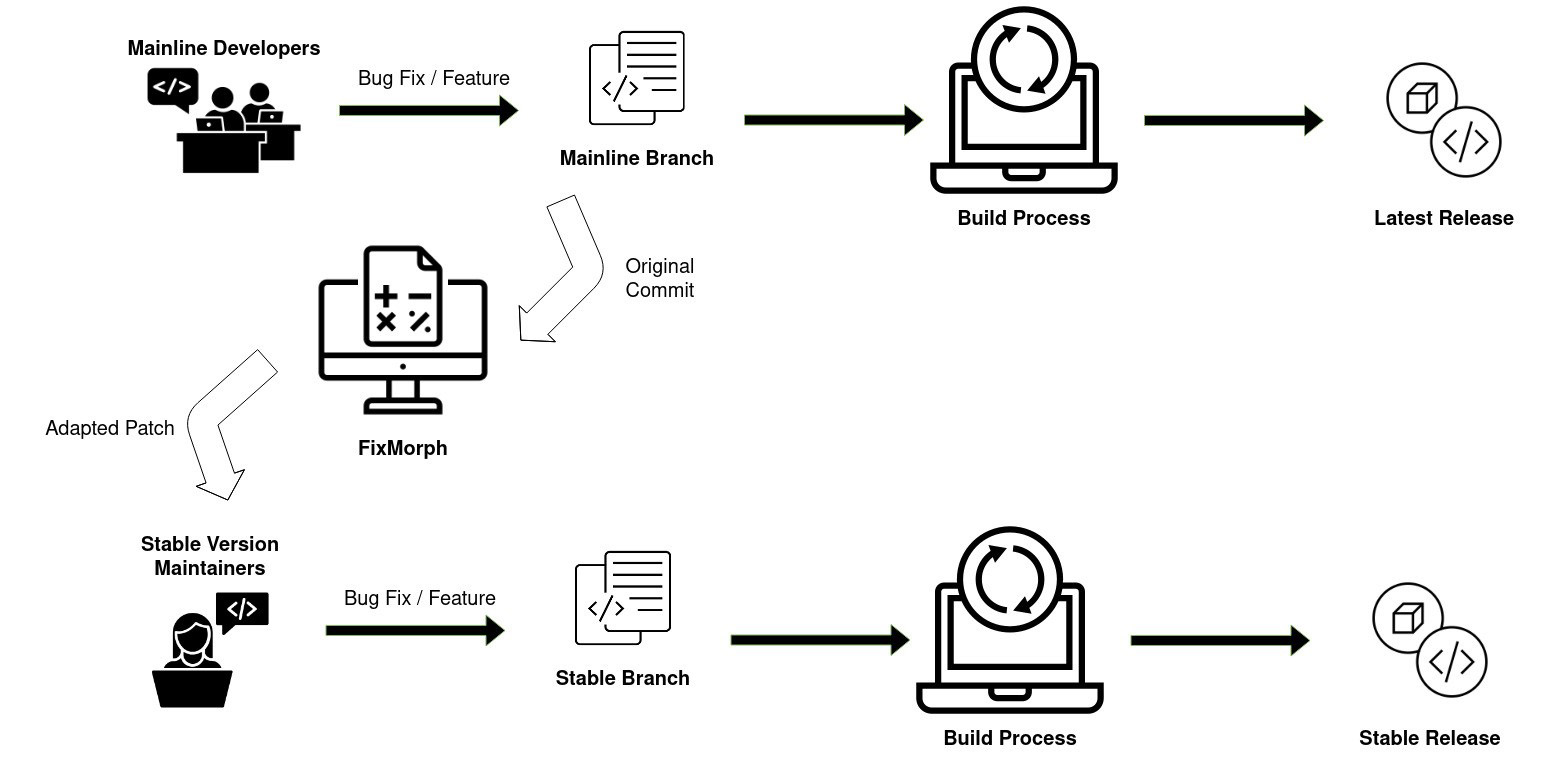
Whenever a bug or vulnerability is detected in the Linux kernel, the kernel developers will endeavour to fix it by introducing a patch into the mainline version of the Linux kernel source tree. However, many users run older “stable” versions of Linux, meaning that the patch should also be “backported” to one or more of these older kernel versions. This process is error-prone and there is usually a long delay in publishing the backported patch. Based on an empirical study, we show that around 8% of all commits submitted to Linux mainline are backported to older versions, but often more than one month elapses before the backport is available. Hence, we propose a patch backporting technique that can automatically transfer patches from the mainline version of Linux into older stable versions. Our approach first synthesizes a partial transformation rule based on a Linux mainline patch. This rule can then be generalized by analysing the alignment between the mainline and target versions. The generalized rule is then applied to the target version to produce a backported patch. We have implemented our transformation technique in a tool called FixMorph and evaluated it on 350 Linux mainline patches. FixMorph correctly backports 75.1% of them. Compared to existing techniques, FixMorph improves both the precision and recall in backporting patches. Apart from automation of software maintenance tasks, patch backporting helps in reducing the exposure to known security vulnerabilities which have not been fixed.
- Automated Patch Backporting in Linux (Experience Paper), Ridwan Shariffdeen, Xiang Gao, Gregory J Duck, Shin Hwei Tan, Julia Lawall, Abhik Roychoudhury, 30th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA) 2021
- Tool: https://github.com/rshariffdeen/FixMorph
- Contact: Ridwan Shariffdeen
Fix2Fit: Crash-avoiding Program Repair
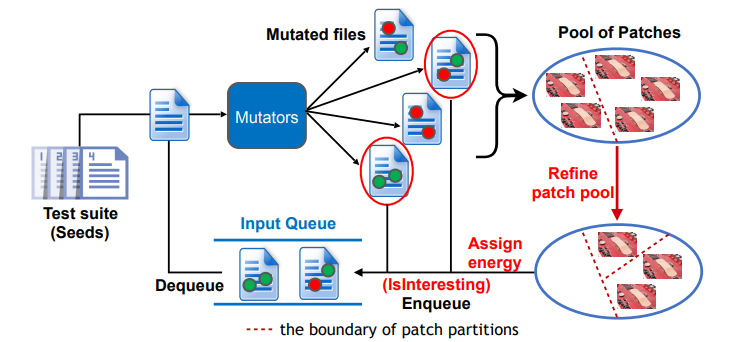 Fuzz testing can also be applied to Automated Program Repair (APR). Specifically, we aim to
address the overfitting problem, which is one of the core challenges for APR. The overfitting
problem occurs when the generated repair/patch satisfies the given test suite, but does not
implement the correct behaviour for inputs outside of the test suite. The repaired program may
not satisfy even the most basic notion of correctness, namely crash-freedom. To address this
issue, our Fix2Fit tool integrates fuzz testing into a program repair framework in order to detect
and discard crashing patches. Our approach fuses test and patch generation into a single
process, in which patches are generated with the objective of passing existing tests, and new
tests are generated with the objective of filtering out over-fitted patches by distinguishing
candidate patches in terms of behavior. We use crash-freedom as the oracle to discard patch
candidates which crash on the new tests. At its core, our approach defines a grey-box fuzzing
strategy that gives higher priority to new tests that separate patches behaving equivalently on
existing tests. This test generation strategy identifies semantic differences between patch
candidates, and reduces over-fitting in program repair. We evaluated our approach on real-world
vulnerabilities and open-source subjects from the Google OSS-Fuzz infrastructure. We found that
our tool Fix2Fit (implementing patch space directed test generation), produces crash-avoiding
patches. While we do not give formal guarantees about crash-freedom, cross-validation with
fuzzing tools and their sanitizers provides greater confidence about the crash-freedom of our
suggested patches. The Fix2Fit project highlights how technologies such as fuzzing can be
combined and applied to other domains such as program repair, which are both relevant to the
overall objectives of the project. Furthermore, program repair is relevant to the year 2 deliverables
of which we have already made progress.
Fuzz testing can also be applied to Automated Program Repair (APR). Specifically, we aim to
address the overfitting problem, which is one of the core challenges for APR. The overfitting
problem occurs when the generated repair/patch satisfies the given test suite, but does not
implement the correct behaviour for inputs outside of the test suite. The repaired program may
not satisfy even the most basic notion of correctness, namely crash-freedom. To address this
issue, our Fix2Fit tool integrates fuzz testing into a program repair framework in order to detect
and discard crashing patches. Our approach fuses test and patch generation into a single
process, in which patches are generated with the objective of passing existing tests, and new
tests are generated with the objective of filtering out over-fitted patches by distinguishing
candidate patches in terms of behavior. We use crash-freedom as the oracle to discard patch
candidates which crash on the new tests. At its core, our approach defines a grey-box fuzzing
strategy that gives higher priority to new tests that separate patches behaving equivalently on
existing tests. This test generation strategy identifies semantic differences between patch
candidates, and reduces over-fitting in program repair. We evaluated our approach on real-world
vulnerabilities and open-source subjects from the Google OSS-Fuzz infrastructure. We found that
our tool Fix2Fit (implementing patch space directed test generation), produces crash-avoiding
patches. While we do not give formal guarantees about crash-freedom, cross-validation with
fuzzing tools and their sanitizers provides greater confidence about the crash-freedom of our
suggested patches. The Fix2Fit project highlights how technologies such as fuzzing can be
combined and applied to other domains such as program repair, which are both relevant to the
overall objectives of the project. Furthermore, program repair is relevant to the year 2 deliverables
of which we have already made progress.
- Fix2Fit: Crash-avoiding Program Repair, Xiang Gao, Sergey Mechtaev, Abhik Roychoudhury, International Symposium on Software Testing and Analysis (ISSTA), 2019
- Tool: https://github.com/gaoxiang9430/Fix2Fit
- Contact: Gao Xiang
Binary Rewriting without Control-Flow Recovery with E9Patch

The backbone of any binary hardening or repair project is the ability to accurately rewrite binary software in order to add/remove functionality. However, binary rewriting is notoriously difficult, with most existing solutions failing to scale to real-world software. To address this issue, the core NSoE-TSS team has developed the E9Patch binary rewriting tool. E9Patch is the first truly scalable binary rewriting tool for x86_64 ELF binaries. E9Patch is based on a combination of novel instruction patching techniques, such as punning, padding and eviction, that operates at the machine code level. These techniques allow E9Patch to insert jumps to trampoline code (implementing some intended binary repair or hardening code) without the need to move existing instructions, thereby preserving the original control flow of the input binary. E9Patch does not need to recover control flow information through static analysis, heuristics or assumptions, thereby eliminating one of the major sources of incompatibility that plague existing state-of-the-art static binary rewriting systems. As such, E9Patch can readily scale to very large binaries (>100MB) including web browsers such as Google Chrome and Firefox.
- Binary Rewriting without Control-Flow Recovery, Gregory J. Duck, Xiang Gao, Abhik Roychoudhury, Programming Language Design and Implementation (PLDI), 2020
- Tool: https://github.com/GJDuck/e9patch
- Contact: Gregory J. Duck
Improved Function Signature Extraction for Optimized Binaries
Control-Flow Integrity (CFI) is a method for program hardening that defends against control-flow hijacking attacks which are commonly used to exploit vulnerable programs. CFI works by enforcing the program’s Control-Flow Graph (CFG) at runtime, meaning that any attempt to divert control-flow to attacker-controlled code will be detected. Hardening binaries with CFI is particularly challenging, given that the CFG can be difficult to extract using analysis, especially for stripped binaries that have been compiled with optimization (-O2/-O3).
To help address the problem of accuracy for binary CFI enforcement, the NSoE-TSS2019-02 team has developed FSROPT---an improved function signature extraction tool for optimized binaries. The tool consists of several components, such as:
- Ground Truth Collection. It is developed as an LLVM pass, which will collect the ground truth of the function signatures including the number and types of arguments for each function and indirect caller.
- Recovered Function Signature Comparison. A comparison between the SMU Classification, an existing tool (TypeArmor), and CFG information from the collected ground truth.
- Improved Function Signature Recovery Policy Enforcement. Implements the improved policy to recover function signatures for each callee and indirect caller based on DynInst.
Further information:
- When Function Signature Recovery Meets Compiler Optimization, Yan Lin, Debin Gao,,Security and Privacy (S&P), 2021.
- Tool: https://github.com/ylyanlin/FSROPT
- Contact: Debin Gao
3. Artificial Intelligence Testing
Artificial Intelligence (AI) has achieved tremendous success in many applications. However, similar to traditional software, AI models can also contain defects, such as adversarial attacks, backdoor and noisy labels. Quality assurance of AI systems is needed. Artificial Intelligence is one of the core competencies of the NSoE-TSS project towards building trustworthy AI systems. This webpage highlights the techniques for evaluating and enhancing the trustworthiness of AI systems including runtime monitor, repair, noisy label handling and adversarial example detection.
Fuzz Testing based Data Augmentation to Improve Robustness of Deep Neural Networks
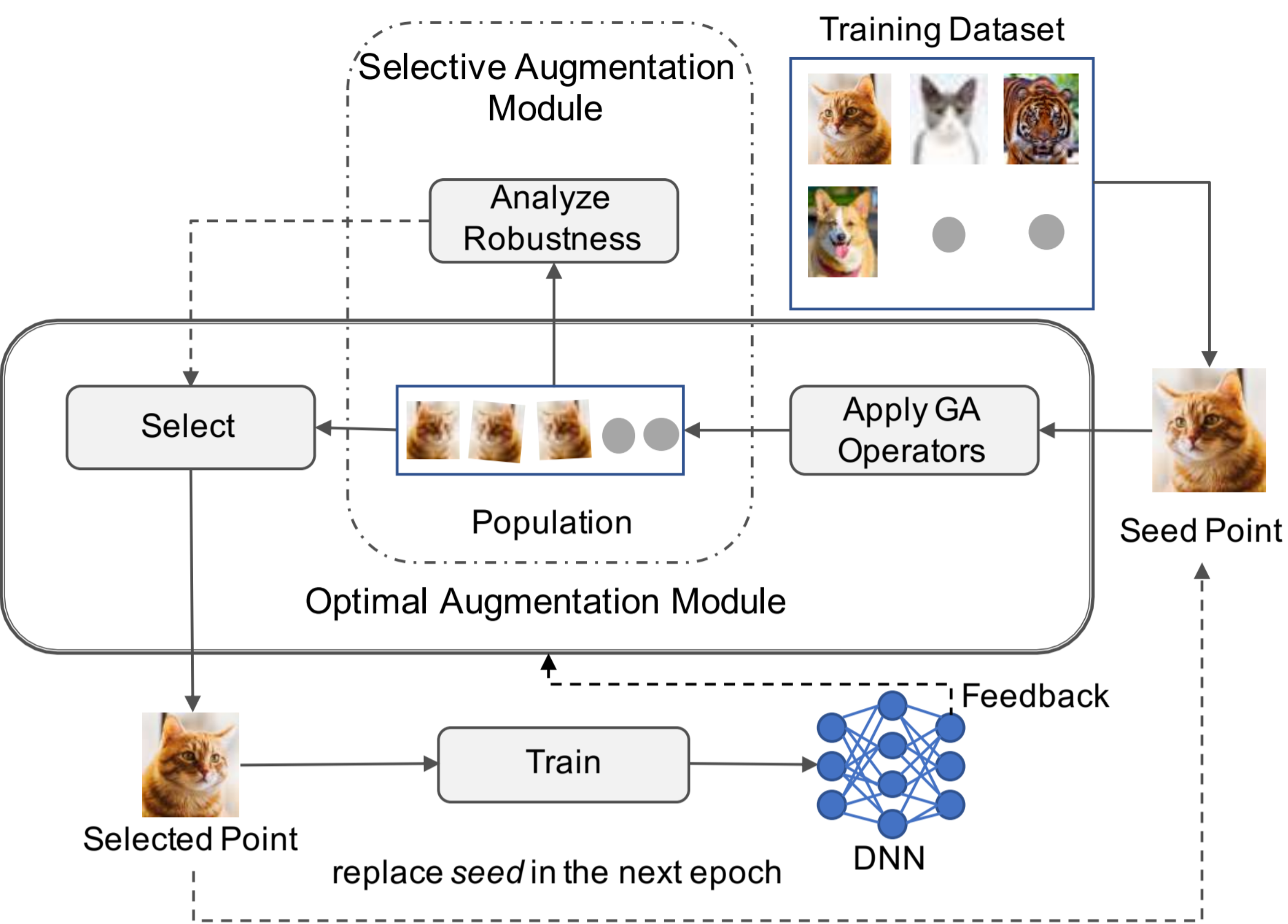 Deep Neural Networks (DNNs) are notoriously brittle with respect to small perturbations in the input data.
The problem is analogous to the overfitting problem in test-based program synthesis and repair, and
is a consequence of incomplete specification(s).
Recently, test generation techniques have been successfully employed to augment existing specifications of intended program
behavior, to improve the generalizability of program synthesis and repair.
Inspired by this approach, we developed the Sensei and Sensei-SA tools based on techniques that repurpose software testing
methods---specifically mutation-based fuzzing---to augment the training data of DNNs, with the objective of enhancing robustness.
Our technique casts the DNN data augmentation problem as an optimization problem, and uses genetic search to generate the most
suitable variant of the input data to use for training the DNN, while simultaneously identifying
opportunities to accelerate training by skipping augmentation in many instances. We evaluate our
tools on 15 DNN models spanning 5 popular image data-sets. Our evaluation shows that Sensei
can improve the robust accuracy of the DNN, compared to the state of the art, on each of the 15
models, by upto 11.9% and 5.5% on average. Further, Sensei-SA can reduce the average DNN
training time by 25%, while still improving robust accuracy.
Deep Neural Networks (DNNs) are notoriously brittle with respect to small perturbations in the input data.
The problem is analogous to the overfitting problem in test-based program synthesis and repair, and
is a consequence of incomplete specification(s).
Recently, test generation techniques have been successfully employed to augment existing specifications of intended program
behavior, to improve the generalizability of program synthesis and repair.
Inspired by this approach, we developed the Sensei and Sensei-SA tools based on techniques that repurpose software testing
methods---specifically mutation-based fuzzing---to augment the training data of DNNs, with the objective of enhancing robustness.
Our technique casts the DNN data augmentation problem as an optimization problem, and uses genetic search to generate the most
suitable variant of the input data to use for training the DNN, while simultaneously identifying
opportunities to accelerate training by skipping augmentation in many instances. We evaluate our
tools on 15 DNN models spanning 5 popular image data-sets. Our evaluation shows that Sensei
can improve the robust accuracy of the DNN, compared to the state of the art, on each of the 15
models, by upto 11.9% and 5.5% on average. Further, Sensei-SA can reduce the average DNN
training time by 25%, while still improving robust accuracy.
- Data Augmentation to Improve Robustness of Deep Neural Networks, Xiang Gao, Ripon K. Saha, Mukul R. Prasad, Abhik Roychoudhury, International Conference on Software Engineering (ICSE), 2020
- Tool: https://sensei-2020.github.io/
- Contact: Gao Xiang
SelfChecker: Self-Checking Deep Neural Networks in Deployment
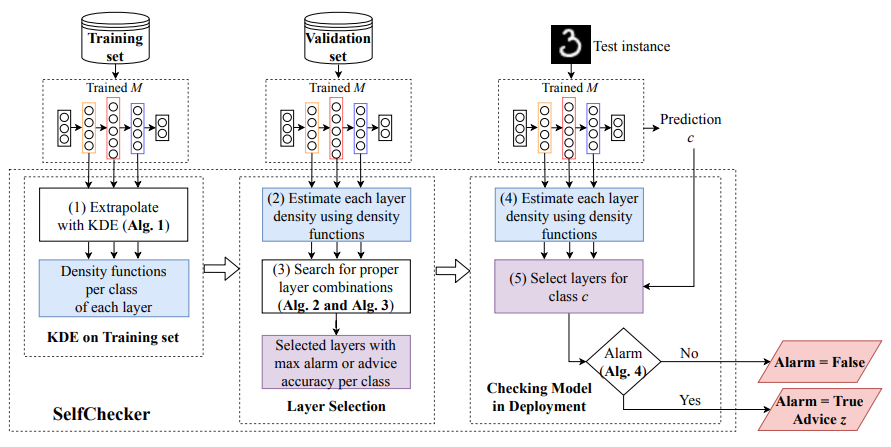 SelfChecker is a self-checking system that monitors DNN outputs and triggers an alarm if the
internal layer features of the model are inconsistent with the final prediction. SelfChecker also
provides advice in the form of an alternative prediction. SelfChecker uses kernel density
estimation (KDE) to extrapolate the probability density distributions of each layer's output by
evaluating the DNN on the training data. Based on these distributions, the density probability of
each layer's outputs can be inferred when the DNN is given a test instance. SelfChecker
measures how the layer features of the test instance are similar to the samples in the training set.
If a majority of the layers indicated inferred classes that are different from the model prediction,
then SelfChecker triggers an alarm. In addition, not all layers can contribute positively to the final
prediction. SelfChecker therefore uses a search-based optimization to select a set of optimal
layers to generate a high quality alarm and advice.
SelfChecker is a self-checking system that monitors DNN outputs and triggers an alarm if the
internal layer features of the model are inconsistent with the final prediction. SelfChecker also
provides advice in the form of an alternative prediction. SelfChecker uses kernel density
estimation (KDE) to extrapolate the probability density distributions of each layer's output by
evaluating the DNN on the training data. Based on these distributions, the density probability of
each layer's outputs can be inferred when the DNN is given a test instance. SelfChecker
measures how the layer features of the test instance are similar to the samples in the training set.
If a majority of the layers indicated inferred classes that are different from the model prediction,
then SelfChecker triggers an alarm. In addition, not all layers can contribute positively to the final
prediction. SelfChecker therefore uses a search-based optimization to select a set of optimal
layers to generate a high quality alarm and advice.
- Self-Checking Deep Neural Networks in Deployment, Yan Xiao, Ivan Beschastnikh, David S. Rosenblum, Changsheng Sun, Sebastian Elbaum, Yun Lin, Jin Song Dong, International Conference on Software Engineering (ICSE), 2021.
- Tool: https://github.com/self-checker/SelfChecker
- Video: SelfChecker
- Contact: Jin Song Dong
DeepHunter: A Coverage-Guided Fuzzer for DeepNeural Networks
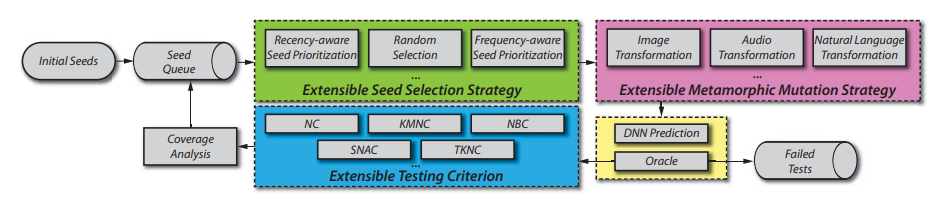
Deep learning (DL) has achieved great success in many cutting-edge intelligent applications. However, like traditional software, DNN-based software could still have defects, which required to be tested especially on safety-critical and security-critical applications. Thus, we have developed DeepHunter, a general-purpose coverage-guided fuzz testing framework for Deep Neural Networks. DeepHunter follows the traditional fuzz testing framework (e.g., AFL) including three main components seed selection, mutation and coverage analysis. In particular, DeepHunter incorporates a metamorphic mutation strategy and a frequency-aware seed selection strategy. The metamorphic mutation aims to generate images, which to a larger extent preserves the test input semantics before and after the mutation. The frequency-aware seed selection strategy is based on the number of times a seed has been fuzzed. DeepHunter is designed to be extensible in the sense that new testing criteria, seed selection strategies and mutation strategies, could be easily implemented and plugged into the framework
- DeepHunter: a Coverage-guided Fuzz Testing Framework for Deep Neural Networks, Xiaofei Xie, Lei Ma, Felix Juefei-Xu, Minhui Xue, Hongxu Chen, Yang Liu, Jianjun Zhao, Bo Li, Jianxiong Yin, Simon See, International Symposium on Software Testing and Analysis (ISSTA), 2019
- Tool: https://bitbucket.org/xiaofeixie/deephunter
- Contact: Liu Yang
Unadversarial Purification:A Defense Tool for Pre-trained Classifiers
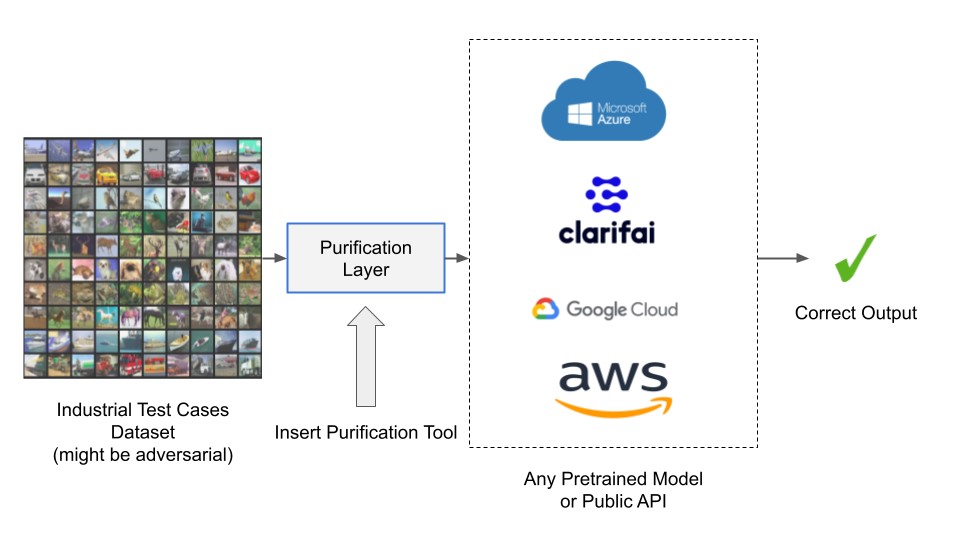
Deep neural networks are known to be vulnerable to adversarial attacks, where a small perturbation leads to the misclassification of a given input. Here, we aim to propose a defense tool called unadversarial-purification to improve adversarial robustness of pre-trained classifiers. This method allows public vision API providers and users to seamlessly convert non-robust pre-trained models into robust ones and it can be applied to both the white-box and the black-box settings of the pre-trained classifier. Most of the existing defenses require that the classifier be trained (from scratch) specifically to optimize the robust performance criterion, which makes the process of building robust classifiers computationally expensive. Therefore, we consider providing a defense tool that robustifies the given pre-trained model without any additional training or fine-tuning of the pre-trained model. In this tool, we design to prepend a custom-trained denoiser before the pre-trained classifier, termed as purification layer. The purification layer is agnostic to the architecture and training algorithm of the pre-trained model, hence can be easily incorporated into well-known public APIs.
- Provably consistent partial-label learning, Lei Feng, Jiaqi Lv, Bo Han, Miao Xu, Gang Niu, Xin Geng, Bo An, Masashi Sugiyama. Proceedings of the Thirty-fourth Annual Conference on Neural Information Processing Systems (NeurIPS’20)
- Tool: https://github.com/AMI-NTU/unadversarial_purification_tool
- Video: Unadversarial Purification
- Contact: Bo An
4. Formal Verification
Formal Verification is an established technique for formally proving the correctness of a system. While other techniques only explore part of the domain under analysis, making it inefficient specially for concurrent systems, formal verification usually aims to cover the entire state space An alternative possible approach is model checking, which automatically explores the state space of a model representing the system to check if it is correct. However model checking often does not scale well for large systems. Instead, it is possible to use deductive verification, which uses theorem provers to generate proof obligations that can be proven automatically often with the help of SMT solvers, or in complex cases, guided by experts. While deductive verification is more expensive, it is especially suited for the verification of high assurance systems, where their correctness is critical.
Formal Verification is a core competency of the NSoE-TSS project. In particular, formal verification in the NSoE-TSS focuses on three different aspects: first, the automation of deductive verification of concurrent systems, specially suited for micro-kernel verification; second, procedures to guarantee the memory safety of programs; and third verification of distributed systems.
Rely-guarantee-based framework for verification of concurrent systems
CSim^2 is a (compositional) rely-guarantee-based framework for the top-down verification of complex concurrent systems in the Isabelle/HOL theorem prover. CSim^2 uses CSimpl, a language with a high degree of expressiveness designed for the specification of concurrent programs. Thanks to its expressibility, CSimpl is able to model many of the features found in real world programming languages like exceptions, assertions, and procedures. CSim^2 provides a framework for the verification of rely-guarantee properties to compositionally reason on CSimpl specifications. Focusing on top-down verification, CSim^2 provides a simulation based framework for the preservation of CSimpl rely guarantee properties from specifications to implementations. By using the simulation framework, properties proven on the top layers (abstract specifications) are compositionally propagated down to the lowest layers (source or machine code) in each concurrent component of the system.
- CSimpl: A Rely-guarantee-based Framework for Verification of Concurrent Systems, David Sanán, Yongwang Zhao, Zhe Hou, Fuyuan Zhang, Alwen Tiu, Yang Liu, International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS), 2017
- Tool: https://github.com/CompSoftVer/CSim
- Contact: Liu Yang
CoSplit: Practical Smart Contract Sharding with Ownership and Commutativity Analysis
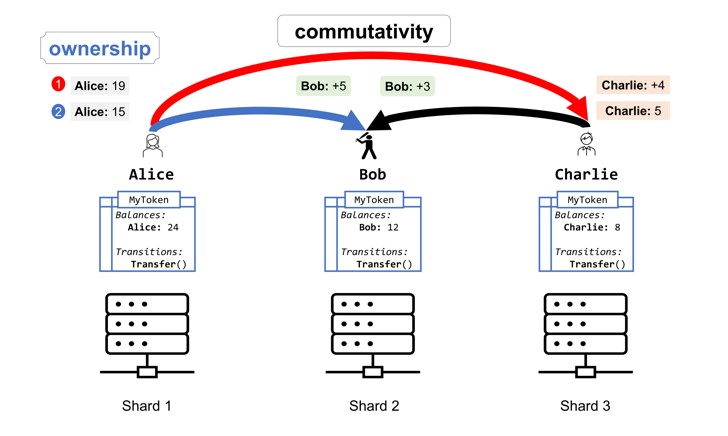
Sharding is a popular way to achieve scalability in blockchain protocols, increasing their throughput by partitioning the set of transaction validators into a number of smaller committees, splitting the workload. Existing approaches for blockchain sharding, however, do not scale well when concurrent transactions alter the same replicated state component—a common scenario in Ethereum-style smart contracts. We propose a novel approach for efficiently sharding such transactions. It is based on a folklore idea: state-manipulating atomic operations that commute can be processed in parallel, with their cumulative result defined deterministically, while executing non-commuting operations requires one to own the state they alter. We present CoSplit—a static program analysis tool that soundly infers ownership and commutativity summaries for arbitrary smart contracts written in the Scilla language and translates those summaries to sharding signatures that are used by the blockchain protocol to allocate shards to transactions in a way that maximises parallelism. We have integrated CoSplit into a state-of-the-art sharded blockchain protocol. Our evaluation shows that using CoSplit introduces negligible overhead to the transaction validation cost, while the inferred sharding signatures allow the system to achieve a significant increase in transaction processing throughput for real-world smart contracts.
- Practical Smart Contract Sharding with Ownership and Commutativity Analysis, George Pîrlea, Amrit Kumar, and Ilya Sergey, 42nd ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI) 2021
- Tool: https://doi.org/10.5281/zenodo.4674301
- Contact: Ilya Sergey