Welcome to Dr. Bingsheng He's Homepage
Research and Publication
Site Navigator: Overview Past Projects Current Projects Publication Selected Publications Back homeResearch Overview
Bingsheng is leading Xtra Computing Group. It is a small group of students and researchers in Singapore, who have been building various computing systems. Xtra's mission is to build faster, greener and cheaper high performance systems. With the passion in system research, Bingsheng strongly believes in prototype implementation and empirical evaluation in addition to theoretical formalization and algorithmic design. As a result, his group and collaborators have developed a number of system prototypes (including Medusa, OmniDB, Mars and FD-tree) that are often requested and used by other researchers. Bingsheng's current research interests range from bare metal hardware-software co-design to distributed systems for massive data processing.- Big data management systems (with special interests in cloud computing and emerging hardware systems such as many-core, GPU, and FPGAs)
- Parallel and distributed systems
- Cloud Computing
- Machine learning systems
Past Projects
Here are some examples of past projects:
 |
Medusa (2010-2015): It is the first system of its kind in Building GPU-based Parallel Sparse Graph Applications with Sequential C/C++ Code. Medusa offers a small set of user-defined APIs, and embraces a runtime system to automatically execute those APIs in parallel on the GPUs. We further develop a series of graph-centric optimizations based on the architecture features of GPU for efficiency. Additionally, Medusa is extended to execute on multiple GPUs within a machine or a cluster. Our empirical studies demonstrate the programmability and efficiency of Medusa for a series of common graph operations. See [TPDS13] [VLDB13BestDemo] |
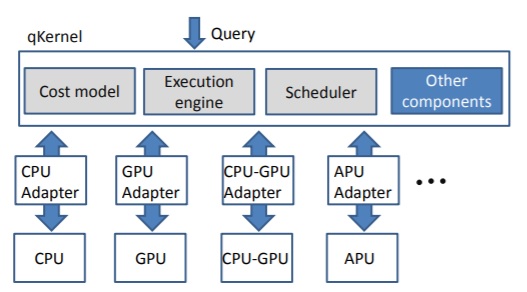 |
OmniDB (2011-2015): Relational databases on emerging many-core architectures (including many-core CPUs, GPUs and APUs) Here are some highlights: a) OmniDB proposes a kernel-adapter based design, a portable yet efficient query processor on parallel CPU/GPU architectures [VLDB13Demo]. b) Two novel designs for taking advange of coupled CPU-GPU architectures (e.g., APUs) [VLDB2013] [VLDB2015]. c) GPL: a pipeline query execution engine [SIGMOD2016]. |
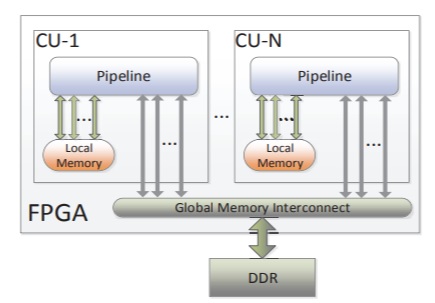 |
ReconfigDB (2013-2016): Hardware-software system design on OpenCL-based FPGAs The vision is to develop bionic parallel systems (e.g., database systems) with superb hardware speed (aka. bare-matal). To achieve this abitious goal, we need novel tools and systems. Example tools: we leverage static and dynamic analysis to develop an analytical performance model, which has captured the key architectural features of FPGA abstractions under OpenCL [HPCA16]. Example systems: databases [FPL2016], graph processing [ongoing]. |
Current Projects
Here are some examples of current projects:
 |
This project develops the next-generation of event stream processing engines. The key motivation is from the big event streams generated by IoT devices. See our publications: BrickStream profiling and benchmark of streaming engines |
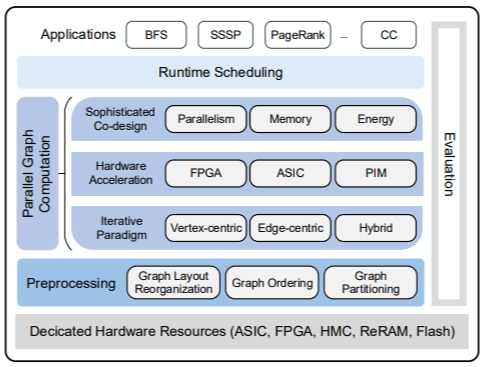 |
This project researches the novel design and implementation of graph accelerators. Due to the complexity of graph processing, the performance and energy efficiency of graph accelerators have been an interesting research topic. See our publications: Survey Novel conflict handling graph engine on FPGA |
|
|
This project examines the design and implementation of machine learning systems under new environments, such as hardware accelerations and federated machine learning. See our publications/systems: hardware accelerations (ThunderSVM and ThunderGBM), and federated machine learning systems (Survey). |
Publication
My publication list: Entry@DBLP Google scholar
Our open-sourced systems can be found at Xtra group Github site.
Selected Publications
Pioneering data management on emerging processors (GPUs/FPGAs).
- Bingsheng He, Ke Yang, Rui Fang, Mian Lu, Naga K. Govindaraju, Qiong Luo, Pedro V. Sander. Relational Joins on Graphics Processors. SIGMOD 2008: ACM SIGMOD International Conference on Management of data, pages: 511-524, 2008. [Impact: a classic paper for GPU-based databases, “Best papers”, invited to ACM TODS.] pdf
- Paul Johns*, Jiong He*, Bingsheng He. GPL: A GPU-based Pipelined Query Processing Engine. SIGMOD 2016: ACM SIGMOD International Conference on Management of data, 2016. [Impact: the most efficient query processor design so far.] pdf
- Zeke Wang^, Bingsheng He, Wei Zhang, Shunning Jiang. A Performance Analysis Framework for Optimizing OpenCL Applications on FPGAs. HPCA 2016: IEEE International Symposium on High Performance Computer Architecture. [Impact: one of OpenCL-based performance tuning tools for FPGAs.] pdf
- Jieru Zhao, Liang Feng, Wei Zhang, Sharad Sinha, Yun (Eric) Liang, Bingsheng He. COMBA: A Comprehensive Model-Based Analysis Framework for High Level Synthesis of Real Applications. ICCAD 2017: 2017 International Conference On Computer Aided Design. [Impact: 2017 IEEE/ACM William J. McCalla ICCAD Best Paper Award (Front End)] pdf
From GPUs/FPGAs to full-stacked hardware systems
- Shen Gao*, Bingsheng He, Jianliang Xu. Real-Time In-Memory Checkpointing for Future Hybrid Memory Systems. ACM ICS 2015: 2015 International Conference on Supercomputing. [Impact: a new paradigm for reliability with NVRAM.] pdf
- Saurabh Jha*, Bingsheng He, Mian Lu, Xuntao Cheng*, Huynh Phung Huynh. Improving Main Memory Hash Joins on Intel Xeon Phi Processors: An Experimental Approach. International Conference on Very Large Data Bases (VLDB) 2015. [Impact: the first in-memory database for Intel many-core processors.] pdf
From databases to other data management
- Jianlong Zhong* and Bingsheng He. Medusa: Simplified Graph Processing on GPUs. IEEE TPDS: IEEE Transactions on Parallel and Distributed System, vol.25, no.6, pp.1543-1552, June 2014, doi: 10.1109/TPDS.2013.111. [Impact: widely cited and “VLDB 2013 best demo”, one of the earliest efficient graph processing systems on the GPU.] pdf
- Kai Zhang^, Bingsheng He, Jiayu Hu, Zeke Wang^, Bei Hua, Jiayi Meng, and Lishan Yang. G-NET: Effective GPU Sharing in NFV Systems. USENIX NSDI: USENIX Symposium on Networked Systems Design and Implementation 2018. [Impact: enabling GPUs as an accelerator for NFV.] pdf
From single-machine to distributed computing/cloud
- Amelie Chi Zhou*, Bingsheng He, Xuntao Cheng*, Chiew Tong Lau, A Declarative Optimization Engine for Resource Provisioning of Scientific Workflows in IaaS Clouds. HPDC'2015: ACM International Symposium on High-Performance Parallel and Distributed Computing. [Impact: improve the programmability of scientific workflows.] pdf
- Rishan Chen*, Xuetian Weng*, Bingsheng He, Mao Yang, Byron Choi, Xiaoming Li, Improving Large Graph Processing on Partitioned Graphs in the Cloud. ACM SOCC'12 (ACM Symposium on Cloud Computing 2012, 21 out of 163). [Impact: one of the very early large graph processing systems] pdf
- Zhaojie Niu*, Bingsheng He, Fangming Liu. Not All Joules are Equal: Towards Energy-Efficient and Green-Aware Data Processing Frameworks. IC2E 2016: IEEE International Conference on Cloud Engineering. [Impact: integrating renewable energy into big-data systems. Best Paper Runner Up of IC2E2016] pdf
Machine learning systems
- Zeyi Wen^, Jiashuai Shi*, Qinbin Li*, Bingsheng He, and Jian Chen. ThunderSVM: A Fast SVM Library on GPUs and CPUs. JMLR: Journal of Machine Learning Research 19 (2018) 1-5. [Impact: ~1000 stars in GitHub, 100x faster than LibSVM] pdf
- Zeyi Wen^, Bingsheng He, Ramamohanarao Kotagiri, Shengliang Lu*, Jiashuai Shi*. Efficient Gradient Boosted Decision Tree Training on GPUs. IEEE IPDPS 2018: IEEE International Parallel & Distributed Processing Symposium. [Impact: ~400 stars in GitHub; GBDT is a popular and competitive approach to deep learning] pdf
This is partial list of awards obtained by Xtra's members.
All Rights Reserved to Bingsheng He © 2019