
Deep Learning for NLP
NUS SoC, 2018/2019, Semester I
CS 6101 - Exploration of Computer Science Research
This course is taken almost verbatim from CS 224N Deep Learning for Natural Language Processing – Richard Socher’s course at Stanford. We are following their course’s formulation and selection of papers, with the permission of Socher.
This is a section of the CS 6101 Exploration of Computer Science Research at NUS. CS 6101 is a 4 modular credit pass/fail module for new incoming graduate programme students to obtain background in an area with an instructor’s support. It is designed as a “lab rotation” to familiarize students with the methods and ways of research in a particular research area.
Our section will be conducted as a group seminar, with class participants nominating themselves and presenting the materials and leading the discussion. It is not a lecture-oriented course and not as in-depth as Socher’s original course at Stanford, and hence is not a replacement, but rather a class to spur local interest in Deep Learning for NLP.
This course is offered twice, for Session I (Weeks 3-7) and Session II (Weeks 8-13), although it is clear that the course is logically a single course that builds on the first half. Nevertheless, the material should be introductory and should be understandable given some prior study.
A discussion group is on Slack. Students and guests, please login when you are free. If you have a @comp.nus.edu.sg, @u.nus.edu, @nus.edu.sg, @a-star.edu.sg, @dsi.a-star.edu.sg or @i2r.a-star.edu.sg. email address you can create your Slack account for the group discussion without needing an invite.
For interested public participants, please send Min an email at kanmy@comp.nus.edu.sg if you need an invite to the Slack group. The Slack group is being reused from previous semesters. Once you are in the Slack group, you can consider yourself registered.
Details
Registration FAQ
- What are the pre-requisites? There are no formal prerequisites for the course. As with many machine learning courses, it would be useful to have basic understanding of linear algebra in probability and statistics. Taking online, open courses on these subjects concurrently or before the course would be advisable if you do not have to requisite understanding.
- Is the course chargeable? No, the course is not chargeable. It is free (as in no-fee). NUS allows us to teach this course for free, as it is not “taught”, per se. Students in the class take charge of the lectures, and complete a project, while the teaching staff facilitates the experience.
-
Can I get course credit for taking this? Yes, if you are a first-year School of Compu ting doctoral student. In this case you need to formally enroll in the course as CS6101, And you will receive one half of the 4-MC pass/fail credit that you would receive for the course, which is a lab rotation course. Even though the left rotation is only for half the semester, such students are encouraged and welcome to complete the entire course.
No, for everyone else. By this we mean that no credits, certificate, or any other formal documentation for completing the course will be given to any other participants, inclusive of external registrants and NUS students (both internal and external to the School of Computing). Such participants get the experience of learning deep learning together in a formal study group in developing the camaraderie and network from fellow peer students and the teaching staff.
- What are the requirements for completing the course? Each student must achieve 2 objectives to be deemed to have completed the course:
- Work with peers to assist in teaching two lecture sessions of the course: One lecture by co-lecturing the subject from new slides that you have prepared a team; and another lecture by moderating of the Slack channel to add materials for discussion.
- Complete a deep learning project. For the project, you only need to use any deep learning framework to execute a problem against a data set. You may choose to replicate previous work orders in scientific papers or data science challenges. Or more challengingly, you may decide to use data from your own context.
-
How do external participants take this course? You may come to NUS to participate in the lecture concurrently with all of our local participants. You are also welcome to participate online through Google Hangouts. We typically have a synchronous broadcast to Google Hangouts that is streamed and archived to YouTube.
During the session where you’re responsible for co-lecturing, you will be expected to come to the class in person.
As an external participant, you are obligated to complete the course to best your ability. We do not encourage students who are not committed to completing the course to enrol.
Meeting Venue and Time
- for Session I (Weeks 3-7): 18:00-20:00, Thursdays, at Seminar Room @ Lecture Theatre 19 (SR@LT19).
- for Session II (Weeks 8-13): 18:00-20:00, Thursdays, at Seminar Room @ Lecture Theatre 19 (SR@LT19).
For directions to NUS School of Computing (SoC) and COM1: please read the directions here, to park in CP13 and/or take the bus to SoC. and use the floorplan to find SR@LT19.
Please eat before the course or during (we don’t mind – like a brown-bag-seminar series), and if you’re parked, you will be able to leave after 7:30pm without paying carpark charges.
People
Welcome. If you are an external visitor and would like to join us, please email Kan Min-Yen to be added to the class role. Guests from industry, schools and other far-reaching places in SG welcome, pending space and time logistic limitations. The more, the merrier.
External guests will be listed here in due course once the course has started. Please refer to our Slack after you have been invited for the most up-to-date information.
NUS (Postgraduate): Session I (Weeks 3-7): Liu Juncheng and 6 other anonymous students.
NUS (Postgraduate): Session II (Weeks 8-13): 4 anonymous students.
NUS (Undergraduate, Cross-Faculty and Alumni): Takanori Aoki, Daniel Biro, Bala, Divakar Sivashankar, Preethi Mohan Rao, Louis Tran, Luong Quoc Trung
WING: Kan Min-Yen, Kee Yuan Chuan
Guests: Chia Keat Loong, Meng-Fen Chiang, Theodore Galanos, Gary Goh, Ang Ming Liang, Jordan Liew, Lim How Khang, Luo Wuqiong (Nick), Mirco Milletari, New Jun Jie (Jet), Pham Nguyen Khoi, Si Chenglei, Praveen Sanap, Yesha Simaria, Tek Yong Jian, Xiao Nan
Schedule
Schedule
Projects
Student Projects
-
Abstractive Summarisation of Long Academic Papers by Si Chenglei, Biro Daniel
 In this project, we use two publicly available datasets to train abstractive summarisation models for long academic papers which are usually 2000 to 3000 words long. We will generate a summary of around 250 words for the papers. We also evaluate different models’ performance.
In this project, we use two publicly available datasets to train abstractive summarisation models for long academic papers which are usually 2000 to 3000 words long. We will generate a summary of around 250 words for the papers. We also evaluate different models’ performance. -
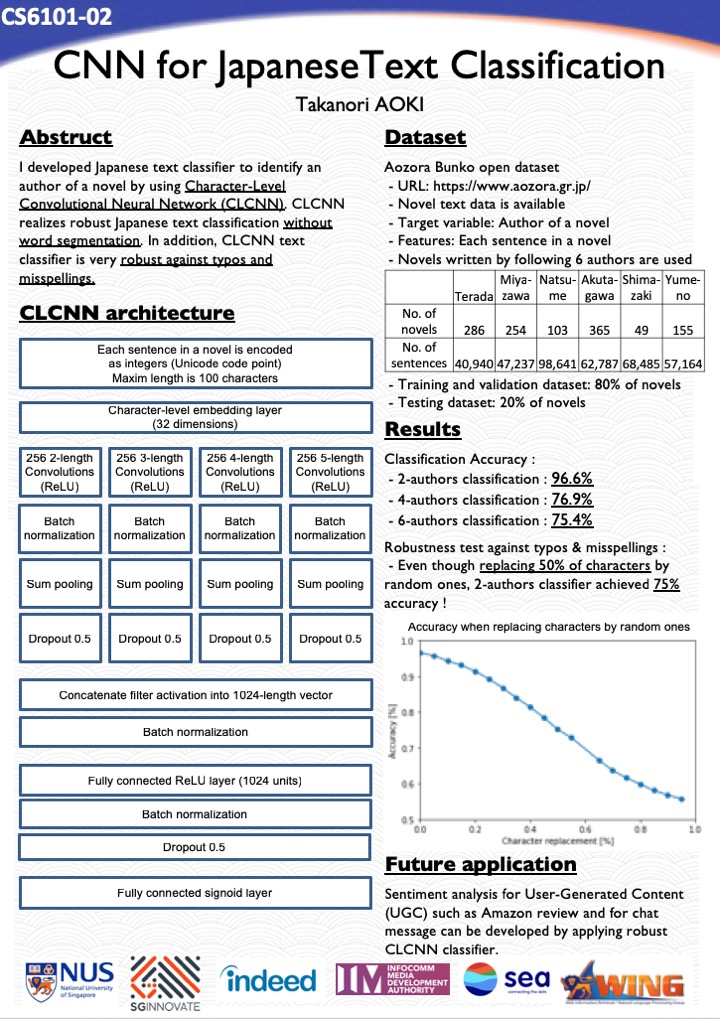
CNN for Japanese Text Classification by Takanori Aoki
 I developed Japanese text classifier to identify an author of a novel by using Character-Level Convoltional Neural Network (CLCNN). CLCNN realizes robust Japanese text classification. In usual way of Japanese text classification, we need to do word segmentation because there is no white space between words in Japanese language. However, CLCNN is applicable without word segmentation. In addition, CLCNN is very robust against typos and misspelling. Results of experimentation will be displayed in STePS.
I developed Japanese text classifier to identify an author of a novel by using Character-Level Convoltional Neural Network (CLCNN). CLCNN realizes robust Japanese text classification. In usual way of Japanese text classification, we need to do word segmentation because there is no white space between words in Japanese language. However, CLCNN is applicable without word segmentation. In addition, CLCNN is very robust against typos and misspelling. Results of experimentation will be displayed in STePS. -
Foreign Exchange Forecasting by Xiao Nan, Luo Wuqiong (Nick), Yesha Simaria, Vikash Ranjan
Award Winner, 2nd Prize
 This project explored forecasting foreign currency exchange price using both historical price data and market news of the trading pair. We first built a market sentiment classifier to obtain daily market sentiment score from market news of the trading pair. To reduce the amount of labelled training data required, we used transfer learning technique by first training a language model using Wikipedia data, then fine-tuning the language model using market news, and finally using the language model as the basis to train the market sentiment classifier. We then combined the market sentiment score and historical price data and fed them in an end-to-end encoder-decoder recurrent neural network (RNN) to forecast foreign exchange trends.
This project explored forecasting foreign currency exchange price using both historical price data and market news of the trading pair. We first built a market sentiment classifier to obtain daily market sentiment score from market news of the trading pair. To reduce the amount of labelled training data required, we used transfer learning technique by first training a language model using Wikipedia data, then fine-tuning the language model using market news, and finally using the language model as the basis to train the market sentiment classifier. We then combined the market sentiment score and historical price data and fed them in an end-to-end encoder-decoder recurrent neural network (RNN) to forecast foreign exchange trends. -
Gaining Insight from News Articles for Stock Prediction by Rahul Rajesh
Award Winner, 1st Prize
 Stock market prediction has been an active area of research for a long time. The Efficient Market Hypothesis (EMH) states that stock market prices are largely driven by new information and follow a random walk pattern. In this study, we test a hypothesis based on the premise of behavioral economics, that the emotions and moods of individuals affect their decision making process, thus, leading to a direct correlation between “public sentiment” and “market sentiment”. We specially look to see if there is any correlation between what people post on twitter and the movement of prices in the stock market. Based off recent happenings in the news, this study is focused on Tesla.
Stock market prediction has been an active area of research for a long time. The Efficient Market Hypothesis (EMH) states that stock market prices are largely driven by new information and follow a random walk pattern. In this study, we test a hypothesis based on the premise of behavioral economics, that the emotions and moods of individuals affect their decision making process, thus, leading to a direct correlation between “public sentiment” and “market sentiment”. We specially look to see if there is any correlation between what people post on twitter and the movement of prices in the stock market. Based off recent happenings in the news, this study is focused on Tesla. -
MC NLP Rap Lyrics Generator by Zhou Yizhuo
Award Winner, 3rd Prize
 Natural language generation is an NLP task which has drawn attention widely in recent years. Besides commercial NLG technology such as chatbot, generating literary works is another interesting application. Some work has been done on writing Shakespeare’s poem and generating paragraph with Harry Potter’s style. As a rap lover, I believe that generating rap lyrics is much more realistic since some rap lyrics written by human are not meaningful. In this project, I start from training a character-level language model using LSTM based on Eminem’s songs’ lyrics dataset which contains around 50000 lines of lyrics. Then I will explore word-level model to examine the new generator’s performance. The ultimate goal of this project is generating several lines of rap lyrics which might be identified as human’s works by testers.
Natural language generation is an NLP task which has drawn attention widely in recent years. Besides commercial NLG technology such as chatbot, generating literary works is another interesting application. Some work has been done on writing Shakespeare’s poem and generating paragraph with Harry Potter’s style. As a rap lover, I believe that generating rap lyrics is much more realistic since some rap lyrics written by human are not meaningful. In this project, I start from training a character-level language model using LSTM based on Eminem’s songs’ lyrics dataset which contains around 50000 lines of lyrics. Then I will explore word-level model to examine the new generator’s performance. The ultimate goal of this project is generating several lines of rap lyrics which might be identified as human’s works by testers. -
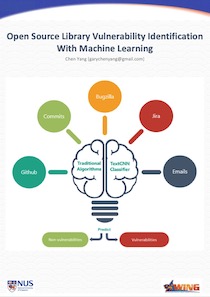
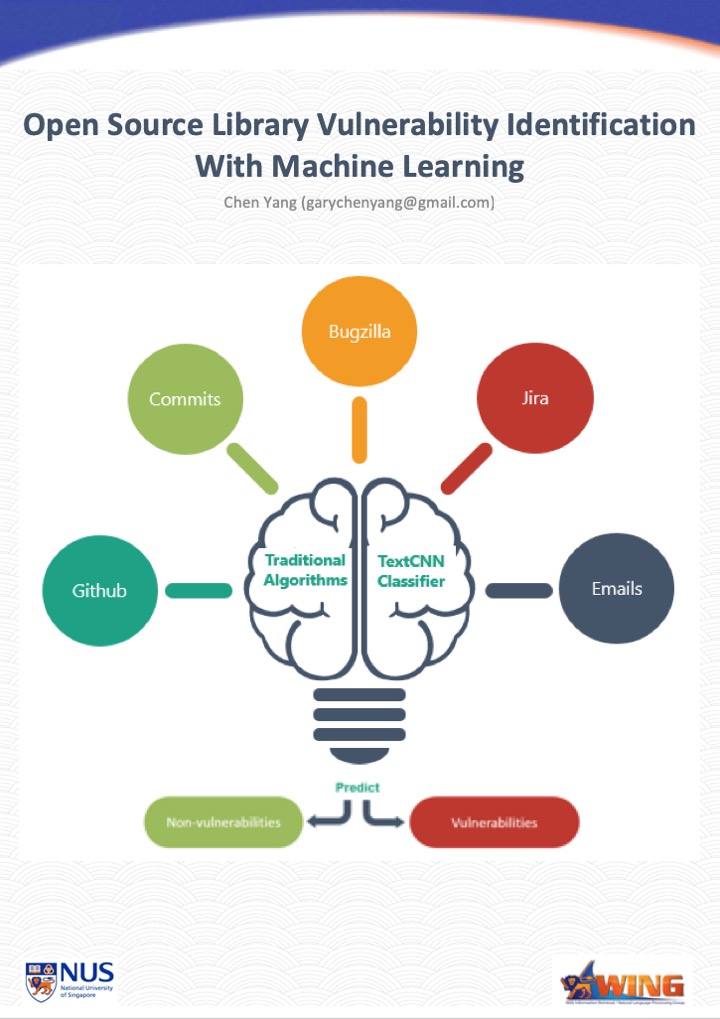
Open Source Software Vulnerability Identification With Machine Learning by Chen Yang
(No poster available, sorry!) There are different data sources we can identify vulnerabilities for open source software. One is the text information from Github issue, Bugzilla , Jira tickets, emails, another is the commit patch. We use traditional machine learning algorithms to identify vulnerability from above source already. Deep learning is used to to identify commits message in this project to compare the result with traditional algorithms. It shows deep learning can get better result even with less features.
-
Reading Comprehension with Lecture Notes by Nguyen Van Hoang, Lee Pei Xuan, Kevin Leonardo, Calvin Tantio, Luong Quoc Trung, Tan Joon Kai Daniel
 This project explores the application of open-domain Question Answering (QA) in learning materials with a contribution of a lecture note dataset, called LNQA, annotated with question-answer pairs. Our approach is to improve the overall pipeline of lecture note reading comprehension involving context retrieving (finding the relevant slides) and text reading (identifying the correct information). Experiments show that initializing our text reader model with a pre-trained version on SQuAD significantly improve its performance on much limited lecture note dataset, comparing with both training from scratch and inferring from the pre-trained model. Narrowing down the search space by specifying departments of questions also helps improve document retriever results, thus we examine state-of-the-art sentence classifiers in predicting departments of questions.
This project explores the application of open-domain Question Answering (QA) in learning materials with a contribution of a lecture note dataset, called LNQA, annotated with question-answer pairs. Our approach is to improve the overall pipeline of lecture note reading comprehension involving context retrieving (finding the relevant slides) and text reading (identifying the correct information). Experiments show that initializing our text reader model with a pre-trained version on SQuAD significantly improve its performance on much limited lecture note dataset, comparing with both training from scratch and inferring from the pre-trained model. Narrowing down the search space by specifying departments of questions also helps improve document retriever results, thus we examine state-of-the-art sentence classifiers in predicting departments of questions. -
Beyond Affine Neurons by Mirco Milletari, Mohit Rajpal
 Recurrent Neural Networks (RNNs) have emerged as one of the most successful framework for time series prediction and natural language processing. However, the fundamental building block of RNNs, the perceptron [1], has remained largely unchanged since its inception: a nonlinearity applied to an affine function. An affine function cannot easily capture the complex behavior of functions of degree 2 and higher. The sum of products signal propagation for the hidden state and current input incorrectly assumes that these two variables are independent and uncoupled. RNNs are increasingly forced to use very large number of neurons in complex architectures to achieve good results. In this project, inspired by Ref. [2], we propose to add simple and efficient degree 2 behavior to Recurrent Neural Network (RNN) neuron cells to improve the expressive power of each individual neuron. We analyze the benefits of our approach with respect to common language prediction tasks. The clear advantage of our approach is fewer neurons and therefore reduced computational complexity and cost. [1] Rosenblatt, Frank. The perceptron, a perceiving and recognizing automaton Project Para. Cornell Aeronautical Laboratory, 1957. [2] Mirco Milletari, Thiparat Chotibut and Paolo E. Trevisanutto. Expectation propagation: a probabilistic view of Deep Feed Forward Networks, arXiv:1805.08786, (2018)
Recurrent Neural Networks (RNNs) have emerged as one of the most successful framework for time series prediction and natural language processing. However, the fundamental building block of RNNs, the perceptron [1], has remained largely unchanged since its inception: a nonlinearity applied to an affine function. An affine function cannot easily capture the complex behavior of functions of degree 2 and higher. The sum of products signal propagation for the hidden state and current input incorrectly assumes that these two variables are independent and uncoupled. RNNs are increasingly forced to use very large number of neurons in complex architectures to achieve good results. In this project, inspired by Ref. [2], we propose to add simple and efficient degree 2 behavior to Recurrent Neural Network (RNN) neuron cells to improve the expressive power of each individual neuron. We analyze the benefits of our approach with respect to common language prediction tasks. The clear advantage of our approach is fewer neurons and therefore reduced computational complexity and cost. [1] Rosenblatt, Frank. The perceptron, a perceiving and recognizing automaton Project Para. Cornell Aeronautical Laboratory, 1957. [2] Mirco Milletari, Thiparat Chotibut and Paolo E. Trevisanutto. Expectation propagation: a probabilistic view of Deep Feed Forward Networks, arXiv:1805.08786, (2018) -
CNN-RNN for Image Annotation with Label Correlations by Xiao Junbin, Hu Zikun, Lim Joo Gek, Tan Kay Pong
 Convolutional Neural Networks (CNNs) have shown great success in image recognition where one image belongs to only one category (label), whereas in multi-label prediction, their performances are suboptimal mainly for their neglection of the label correlations. Recurrent Neural Networks (RNNs) are superior in capturing label relationships, such as label dependency and semantic redundancy. Hence, in this project we implement a CNN-RNN framework for multi-label image annotation by exploiting CNN’s capability for image-to-label recognition and RNN’s complement in label-to-label inference. We experiment on the popular benchmark IAPRTC12 to show that CNN-RNN can help improve the performance on the CNN baseline.
Convolutional Neural Networks (CNNs) have shown great success in image recognition where one image belongs to only one category (label), whereas in multi-label prediction, their performances are suboptimal mainly for their neglection of the label correlations. Recurrent Neural Networks (RNNs) are superior in capturing label relationships, such as label dependency and semantic redundancy. Hence, in this project we implement a CNN-RNN framework for multi-label image annotation by exploiting CNN’s capability for image-to-label recognition and RNN’s complement in label-to-label inference. We experiment on the popular benchmark IAPRTC12 to show that CNN-RNN can help improve the performance on the CNN baseline. -
Reading Wikipedia to Answer Open-Domain Questions by Nguyen Ngoc Tram Anh, Louis Tran, Jet New, Leong Kwok Hing, Tran Minh Hoang
 no abstract submitted. Original Author: Danqi Chen, Adam Fisch, Jason Weston and Antoine Bordes.
no abstract submitted. Original Author: Danqi Chen, Adam Fisch, Jason Weston and Antoine Bordes. -
Source Code Comment Generation by Praveen Sanap
 The number of high quality, well documented, open sources projects has only increased. I propose that, with the advances in NLP, a deep learning model can learn to make comments for a source code from such data.
The number of high quality, well documented, open sources projects has only increased. I propose that, with the advances in NLP, a deep learning model can learn to make comments for a source code from such data. -
Axiomatic attribution for neural translation by Ang Ming Liang, Ang Chew Hoe
 The recent success of Neural Machine Translators (NMT), have shown the power of using neural approaches to the problem of machine translation. Nonetheless, one of the biggest problems if NMT and deep learning models in general is their lack of interpretability. In light of this, this projects aims to “unbox” the black box of widely use NMT models using the axiomatic attribution framework proposed by M Sundarajan et al 2017.
The recent success of Neural Machine Translators (NMT), have shown the power of using neural approaches to the problem of machine translation. Nonetheless, one of the biggest problems if NMT and deep learning models in general is their lack of interpretability. In light of this, this projects aims to “unbox” the black box of widely use NMT models using the axiomatic attribution framework proposed by M Sundarajan et al 2017. -
Legal Text Classifier with Universal Language Model Fine-tuning by Lim How Khang
 Recent work has shown that pre-training a neural language model on large public text datasets improves the accuracy of a neural text classifier while requiring fewer labelled training samples. We use the Universal Language Model Fine-tuning method introduced by Howard and Ruder (2018)* to train a legal text classifier to perform 19-way legal topic classification on a dataset of 3,588 legal judgments issued by the Singapore Court of Appeal and High Court.
Recent work has shown that pre-training a neural language model on large public text datasets improves the accuracy of a neural text classifier while requiring fewer labelled training samples. We use the Universal Language Model Fine-tuning method introduced by Howard and Ruder (2018)* to train a legal text classifier to perform 19-way legal topic classification on a dataset of 3,588 legal judgments issued by the Singapore Court of Appeal and High Court.










{kind=link}
Other Links
- Deep Learning for NLP using Python (Git Repo) - https://github.com/rouseguy/europython2016_dl-nlp
- Deep Learning, an MIT Press book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville - http://www.deeplearningbook.org/
- Neural Networks and Deep Learning - free e-book by Michael A. Nielsen - http://neuralnetworksanddeeplearning.com/
- Fast.AI website - http://www.fast.ai/
- Fast.AI Discourse Forums - (http://forums.fast.ai/)
- AI Saturdays in Singapore, sponsored by SG Innovate - https://sginnovate.com/events/ai-saturdays
Previous CS6101 versions run by Min:
- Deep Learning via Fast.AI - http://www.comp.nus.edu.sg/~kanmy/courses/6101_2017_2/
- Deep Learning for Vision - http://www.comp.nus.edu.sg/~kanmy/courses/6101_2017/
- Deep Learning for NLP - http://www.comp.nus.edu.sg/~kanmy/courses/6101_2016_2/
- MOOC Research - http://www.comp.nus.edu.sg/~kanmy/courses/6101_2016/