Instructions
Unlike high-level programming languages, each instruction in MIPS assembly language executes a simple command. While there are usually counterpart to each MIPS instruction in high-level programming languages, the other opposite is not true. In other words, some instructions in high-level programming languages have no counterpart in MIPS.
This can usually be remedied by having two or more MIPS instructions. Since each line of assembly code contains at most 1 instruction, this means that a single line in high-level language may correspond to more than 1 MIPS instructions. This is one of the many reasons why translating from assembly back to high-level language is extremely difficult.
Since the assembly language is still pretty much intended for human to read, we can have comments in the code.
Comments start with hex sign (i.e., #) and ends until end of line.
So, anything from # until the end of the line will be ignored by the assembler.
General Syntax
There are 5 general instruction syntax for MIPS:
- R-instruction:
op $reg, $reg, $reg - I-instruction (immediate):
op $reg, $reg, value - I-instruction (branch):
op $reg, $reg, label - I-instruction (memory):
op $reg, value($reg) - J-instruction:
op label
Note that MIPS operations are mainly register-to-register.
Here, the op is the operation (also called the opcode).
Any registers are denoted by $reg.
We can choose to use either the register name or the register number.
value are typically 16-bits values which can be either in hexadecimal or integers.
Whether or not they are signed or unsigned depend on the operation we are performing.
Lastly, label are program labels, which can be added before any instruction:
label: op $reg, $reg, $reg
Labels are not part of the actual machine code instruction.
In particular, they will be replaced by value by the assembler.
And so, all the I-instruction will actually look similar after assembly.
The final form will be similar to the second type op $reg, $reg, value.
General Memory Organisation
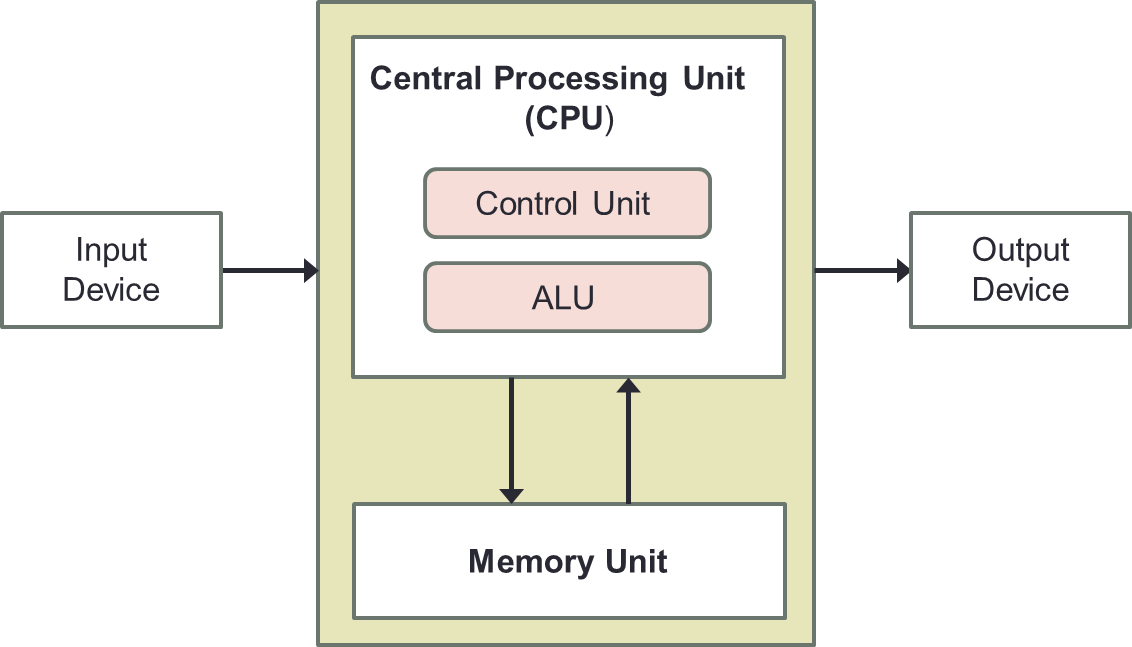
Recap the von Neumann architecture. Here, the memory unit is currently like a black-box. However, the main memory can be viewed as a large, single-dimension array of memory locations. Each location of the memory has an address, which is an index into the array. So, given k-bit address, the address space is of size 2k.
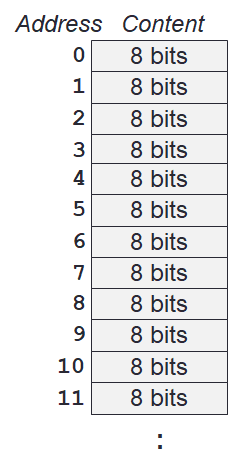
This can also be viewed logically as the image on the right. The memory map on the right contains one byte (i.e., 8-bits) in every location/address. This is called byte addressing.
Transfer Unit
Using distinct memory address, we can access either of the following:
- A single byte (byte addressable).
- A single word (word addressable).
where a word is:
- usually 2n bytes.
- the common unit of transfer between processor and memory.
- the same size as the register, the integer size and instruction size (in general, for most architectures).
Word Alignment
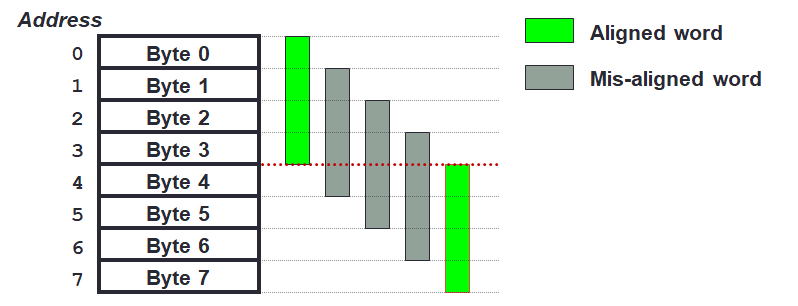
Words are aligned in memory if they begin at a byte address that is a multiple of the number of bytes in a word. For instance, if a word consist of 4 bytes, then the green words are aligned while the greyish green words are misaligned.
Word Align Check
How do we quickly check whether a given memory address is word-aligned or not?
We check if the value of the address modulo word size is equal to 0. If a word is 2n bytes, we can use the bitwise AND operation to bitmask everything except the last n-bits. We then check if the last n-bits are all 0s.