
20 October 2021 – Shaw Senior Professor Tan Kian-Lee and Associate Professor Xiao Xiaokui have won Best Paper awards at the 47th International Conference on Very Large Data Bases, held both online and onsite in Copenhagen, Denmark from 16 to 20 August 2021.
Prof Tan won the Best Scalable Data Science Paper Award for the paper titled, ‘Optimising Bipartite Matching in Real‐World Applications by Incremental Cost Computation’, while A/P Xiao won the Best Research Paper Award for the paper titled, ‘Scaling Attributed Network Embedding to Massive Graphs’.
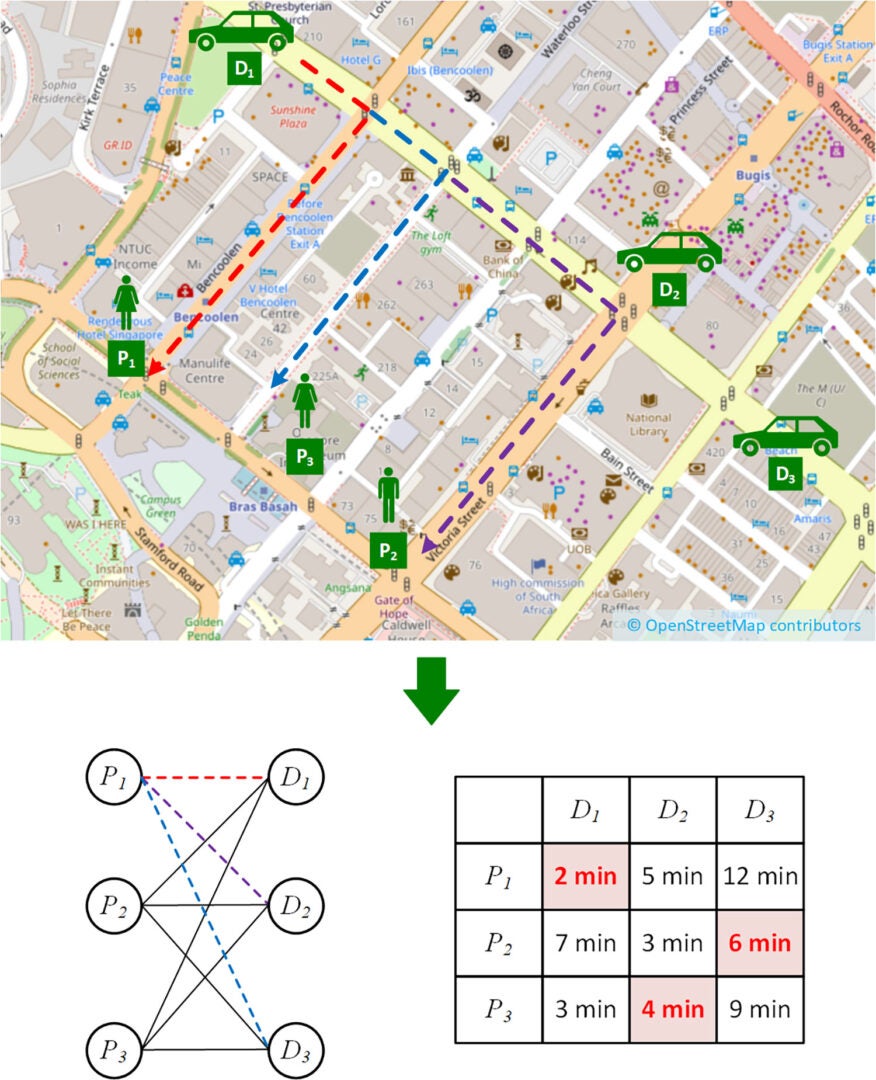
Reducing assignment costs of ride-hailing services
In ride‐hailing services, a car has to be assigned to a passenger request quickly. Given a set of passengers and a set of cars, assigning cars to passengers in the most optimal way (such as to minimise the total wait time) can be modeled as a minimum cost bipartite matching problem.
The Kuhn-Munkres (KM) algorithm is commonly used in ride-hailing services to assign cars to passenger requests – however, according to Prof Tan, the impact of edge cost computation is often overlooked.
“The KM algorithm assumes that the edge costs between all bipartite pairs are available, and ignores the impact of edge cost computation. However, in reality, the cost of edge computation often significantly outweighs the cost of the computation of the optimal assignment itself,” said Prof Tan.
He added: “For ride‐hailing services in particular, assigning drivers to passengers involves the computation of expensive graph shortest paths in real time. The problem is exacerbated by the continuous recomputation of edges (since shortest paths change due to the dynamism of the network) and the scale of the requests/drivers (i.e., large number of edges).”
To combat this, Prof Tan worked with Tenindra Abeywickrama and Victor Liang from the Grab-NUS AI Lab to develop two variants of the KM algorithm, which incrementally compute edge costs on an inexpensive, lower‐bound heuristic.
“We observed that many real‐world applications exhibit high spatial locality of matching. For example, in ride-hailing services, it is unlikely that a driver will be assigned to a passenger who is a significant distance away. Using this intuition, we only need to compute edges that are most likely to be in the optimal matching,” said Prof Tan.
“Our variants still compute the exact optimal matching, but at a significantly lower overall running time,” he added, “and can be used as a drop‐in replacement for any optimal assignment framework that uses KM as a subroutine.”
Developing a scalable approach for attributed network embedding (ANE) computation
Attributed network embedding (ANE) can be used in downstream machine learning tasks to map graph nodes to compact vectors.
However, it is challenging to obtain high-utility embeddings that enable accurate predictions, an issue which is made more difficult when scaling effective ANE computation to massive graphs with millions of nodes.
“Existing solutions largely fail on such graphs, leading to prohibitive costs, low-quality embeddings, or both,” said A/P Xiao.
To solve this problem, he worked with NUS Computing Research Fellow Yang Renchi, Computer Science PhD student Liu Juncheng, and three other collaborators to develop PANE, an effective and scalable approach to ANE computation for massive graphs.
“PANE obtains high scalability and effectiveness through three main algorithmic designs. First, it formulates the learning objective based on a novel random walk model for attributed networks. Second, PANE includes a highly efficient solver for the above optimisation problem, whose key module is a carefully designed initialisation of the embeddings, which drastically reduces the number of iterations required to converge. Finally, PANE utilises multi-core CPUs through non-trivial parallelisation of the above solver, which achieves scalability while retaining the high quality of the resulting embeddings,” said A/P Xiao.
He added: “Extensive experiments, comparing 10 existing approaches on 8 real datasets, demonstrate that PANE consistently outperforms all existing methods in terms of result quality, while being orders of magnitude faster. On the large Microsoft Academic Knowledge Graph (MAG) dataset with over 59 million nodes, 0.98 billion edges, and 2,000 attributes, PANE is the only known viable solution that obtains effective embeddings on a single server, within 12 hours.





























