
7 July 2021 – Five NUS Computing graduates recently received the Outstanding Undergraduate Researcher Prize (OURP) for the 2020/2021 Academic Year.
Four Computer Science graduates, Lee Yiyuan, Nelvin Tan Thong Cai, Zhang Yuntong, and Ling Yan Hao, along with Business Analytics graduate, Risa Lim Ning, each won the OURP for their Final Year Projects (FYPs).
FYPs are year-long projects that are usually undertaken at the final year of an undergraduate programme.
The OURP is an annual, university-wide competition to encourage research and to recognise the best undergraduate researchers in NUS. Projects are evaluated based on criteria such as the originality and significance of the project, and evidence of critical and independent thinking.
Award recipients each receive a cash prize of SGD $2,000.
Speeding up reasoning for complex robotic tasks

Computer Science graduate Lee Yiyuan received the OURP for his FYP on speeding up reasoning for complex robotic tasks.
“Long-horizon reasoning is important for many robotics tasks. For example, to drive a car through a crowd, we need to reason ahead of time to avoid collisions. Unfortunately, it is hard for a robot to do so – there are many possible actions for each time step, and having to consider all the possible combinations over a horizon leads to an exponential complexity that is infeasible to deal with,” explained Lee.
To tackle this problem, Lee’s project focuses on identifying action sequences that are useful for robots, and getting robots to focus on them instead of the redundant action sequences.
In his paper, Lee proposed an algorithm called Macro-Action Generator-Critic (MAGIC). MAGIC helps robots learn macro-actions through feedback. These macro-actions include local trajectories that manoeuvre an autonomous car past other nearby cars. In turn, the robots use these learned macro-actions to condition long-horizon planning.
Calling it a “unique and novel approach”, Lee explained that the selected action sequences are directly optimised to maximise the effectiveness of the complex reasoning process, instead of using auxiliary human-defined criteria.
This is done by combining recent advancements in reinforcement learning, and classical state-of-the-art decision-making algorithms.
“This produces a powerful approach that leverages on both explicit reasoning and past experience, and yields optimal performance in robots,” said Lee, who was supervised by Professor David Hsu.
As a result, the robots in the experiment were able to outperform robots with manually-specified action sequences, and even humans.
Success did not come easy for Lee. Due to the COVID-19 pandemic and tightening of restrictions, he could not conduct his experiments at the lab. So, he had to turn his hostel room into a lab, and resorted to using his bed frame as an experiment table for one of the tasks.
“I had to run experiments in a crammed room under the 30-degree sun for almost five hours daily over an entire week. I also had to sleep on the floor. The experience was not the most pleasant, but will definitely remain memorable for years to come,” said Lee.

Lee’s paper was also accepted in the prestigious annual Robotics: Science and Systems (RSS) 2021 conference, which is due to take place online in mid-July this year.
“As an undergraduate, having a paper accepted into RSS would normally only be a dream. I was certainly euphoric upon learning the results. I had thoroughly enjoyed the process, and the news of the acceptance was certainly the cherry on the cake. It made me love robotics research even more, and I definitely will be doing this for a long time,” said Lee. “I want to thank my supervisor, Prof David Hsu, as well as my fellow lab mates who have helped me throughout this journey, especially Dr. Cai Panpan and Dr. Luo Yuanfu.”
He believes the unique approach to problem-solving, and real-world application of the algorithm, made his work stand out.
“We managed to successfully develop a bold idea that is almost completely original, and where there are very few works of similar kind in the literature. Second, we made it work on an actual robot and on realistic robotics tasks, validating our approach as a practical one. This makes it much more applicable than a considerable portion of related computer science research projects today, which focus only on Atari games and simplified simulators with little real-world application,” said Lee.
Efficient algorithms for group testing under practical considerations

As part of his FYP, Computer Science graduate Nelvin Tan Thong Cai sought to develop and analyse efficient group testing algorithms under challenging settings that better account for crucial, real-life situations.
Tan describes group testing as having far-reaching applications—its most apparent use being in the medical field, such as in COVID-19 testing.
In the medical field, testing individuals individually for a rare disease is often expensive, or impossible due to limited test resources.
To alleviate the issues of cost and limited resources, group testing is conducted by conducting a single test on a pool of samples, such as blood or saliva, from a group of different individuals. Thus, an entire pool of people may be ‘cleared’ (of a particular disease/virus) or excluded with a single negative test.
This raises two important questions: how to design the test pools, and how to identify which individuals are infected or healthy, given the test results. Advances in group testing algorithms have addressed these two questions, but other important practical questions such as how efficient the identification algorithms can be, and how much computer memory such algorithms need, have received relatively less attention.
Therefore for his project, Tan studied two variants of group testing under these conditions. First, in a “noisy” setting, in which the group testing outcomes are not “perfectly reliable”. The second setting is a “constrained” setting, in which each individual can only be placed in a small number of tests, and/or each testing pool size must be below a specified value, to simulate conditions such as testing equipment limitations.
“In each of these settings, we provide the first algorithms known to maintain near-optimality not only in terms of the number of tests, but also in terms of the algorithmic runtime and computer storage requirements,” said Tan.
He believes that his theory-focused paper, and the significant results from his project, earned him the OURP award, as well as the paper’s acceptance at the International Symposium on Information Theory (ISIT), which will be held virtually in mid-July this year.
“Unlike most of the projects, my project is not application-oriented, but instead focuses on the fundamental mathematical theory (e.g., algorithms and performance limits), which is of interest to researchers in numerous fields including information theory, statistics, and theoretical computer science,” he added.
Tan credits his success to his project supervisor. “I felt grateful and honoured when I learnt about the results. Winning the prize led me to reflect on the things that went well during the project. More specifically, I had the honour of working under an immensely supportive supervisor, Prof Jonathan Scarlett, who provided me with critical advice that opened new ways of thinking about the problem at hand,” he said.
Exploring how algorithmic agents teach and learn

Computer Science graduate Ling Yan Hao’s project involved understanding how algorithmic agents (typically used in applications such as robots) interact with and learn from each other, from a mathematical perspective.
“We study a simple social learning problem involving two agents, a “teacher” and a “student”. The teacher gradually learns about the environment and conveys this information to the student to facilitate learning as quickly as possible. The challenge is that the teacher’s measurements is not perfectly reliable – for example, due to imperfect sensors, and neither is the communication channel to the student, since essentially all real-world communication channels introduce imperfections that need to be overcome through communication codes,” explained Ling, who was also supervised by Assistant Professor Jonathan Scarlett for his FYP.
“My main independent contribution was to find an optimal strategy, in the sense that the student is able to learn at a certain rate (i.e., speed) that is provably mathematically impossible to improve further,” added Ling. “I personally found this result very surprising, as another research paper published recently conjectured that this optimal strategy should not be achievable.”
Ling’s research paper was also accepted at the International Symposium on Information Theory (ISIT), which will take place in mid-July online this year.
Protecting software from memory errors & hackers

Memory errors in software systems remain one of the most dangerous software errors since the 1970s.
These errors are particularly dangerous, as they frequently occur in important and widely used software systems, such as critical infrastructure software, including operating systems and web servers or browsers.
Currently, researchers only have partial solutions to mitigate the potential exploitation of such errors by hackers. Such partial solutions involve using a single technology, which manages to detect only a subset of memory errors present.
For his FYP, Computer Science graduate Zhang Yuntong developed a better solution to protect software from memory errors and prevent further exploitation.
“The most effective defences for software require source code, but it is not applicable when the software does not come with source code, which is what happens for most commercial off-the-shelf (COTS) software. Our project looks at practical protection of software in COTS form,” explained Zhang, who was supervised by Associate Professor Roland Yap, and also worked closely with Assistant Professor Gregory J. Duck on the project.
In their paper, they proposed combining two state-of-the-art memory error detection techniques, AddressSanitizer RedZones and LowFat, to provide stronger security protection against more types of memory errors using their complementary strengths. The resulting tool is called RedFat.
“We implemented our approach in the form of a tool, RedFat, with several optimisations to reduce the overhead introduced to the software under protection,” said Zhang. The overhead in this situation refers to the slowing down of a software when RedFat protection is enabled.
RedFat was evaluated against Standard Performance Evaluation Corporation (SPEC) benchmarks to demonstrate its efficiency, and proved capable of protecting large binaries such as the Google Chrome browser. The SPEC benchmarks are designed to provide performance measurements for computer systems.
“When enabling protection on the more critical write operations, RedFat incurs only an average slowdown of 55%, which makes it practical to be deployed in the real world,” added Zhang. “A user can potentially use RedFat to protect the commonly used COTS software on his or her computer.”
With the RedFat protection in place, when a malicious hacker finds a memory error in the protected software and tries to exploit the error, RedFat will report the malicious action and abort the execution of software to prevent the hacker from doing serious damage to the system.
Helping patients avoid Adverse Drug Events

In healthcare, adverse drug events (ADEs) are unwanted and dangerous side effects that patients may experience following certain medical treatments. They include adverse drug reactions and allergic reactions, and can lead to dangerous injuries in patients. ADEs are also often preventable, but when they occur, they cause billions in losses annually.
ADEs are commonly mentioned in hospital discharge summaries. However, given the large number of patients healthcare professionals attend to each day, it is impractical for them to analyse each patient’s discharge sheet and identify these ADE mentions.
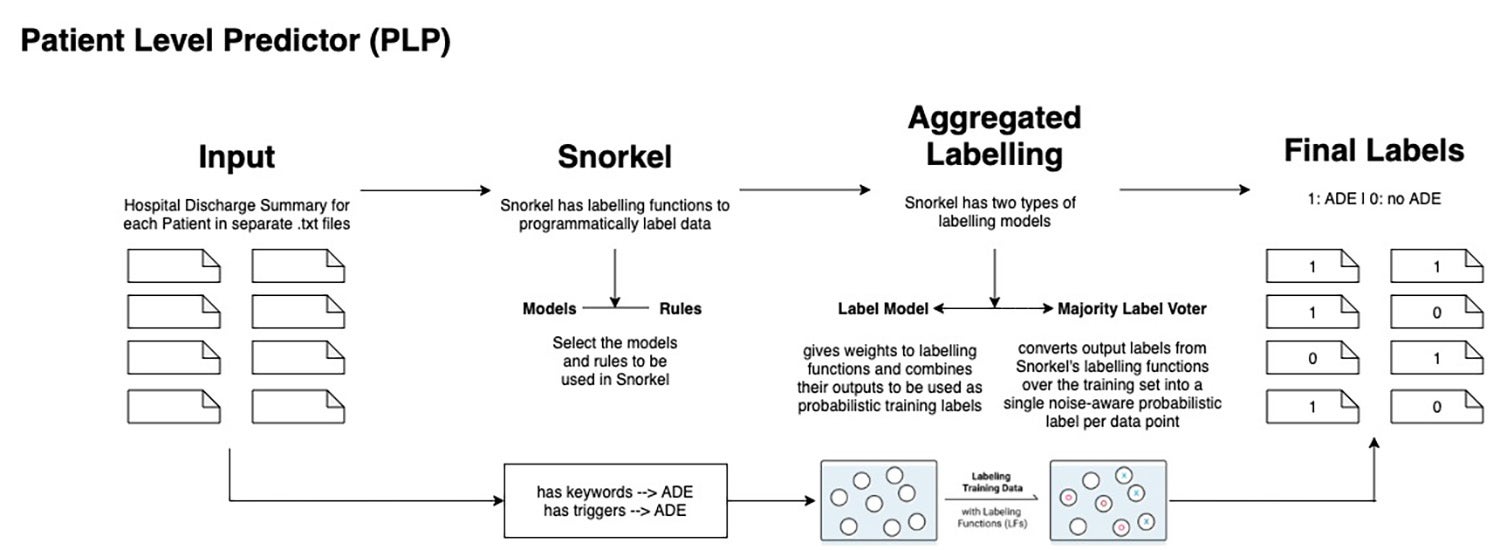
To tackle this pressing problem, Business Analytics graduate Risa Lim Ning implemented an end-to-end semi-supervised pipeline, named Patient Level Predictor (PLP).
The PLP identifies ADEs in hospital discharge summaries using a mixture of supervised models and rules, and helps healthcare professionals avoid the time-consuming process of labelling and summarising them.
In addition, it has the potential to help medical experts find more ADEs with significantly less time and effort. It can also be easily integrated into the Clinical Decision Support System, a system used by hospitals in Singapore to mine ADEs from clinical notes.
Once the labels generated by the PLP are validated by experts, they can be flagged in a patient’s file and may prove extremely useful when diagnosing a patient, who may be in a life-threatening situation.
The PLP was also designed to be easily customised and improved, with users being allowed to add new models and rules, based on clinical expertise, to the system.
Despite running into a few issues earlier on in her project, Lim continued to plough on.
“Through the mid-way mark, the initial results were not promising or satisfactory, which was disappointing. However, after rigorously experimenting many design choices, the final model actually outperformed more complex state-of-the-art models for the same problem,” said Lim.
Lim’s FYP is part of a larger project helmed by Assistant Professor Vaibhav Rajan, whose research areas include healthcare informatics and intelligent systems.
“His guidance and mentorship were instrumental in the project’s success. I really want to thank Prof Rajan for providing the valuable weekly consultation sessions that helped the project progress smoothly and effectively,” added Lim. “After working on the project for a year, seeing it all come together and perform well was extremely rewarding. I felt that my efforts paid off, and the potential positive impact of my solution started to weigh in on me.”





























Assistant Professor Yair Zick: Ethics in Artificial Intelligence